- VMware Technology Network
- :
- Cloud & SDDC
- :
- VMware vSphere
- :
- VMware vSphere™ Discussions
- :
- Running out of space inexplicably
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Running out of space inexplicably
datastore1 is 9TB in size. I only have one Windows server in there that I created with two drives, C=50GB and D=8TB. Twice already it ran out of space and made the server inaccessible. I did some digging around and followed a suggestion to remove any snapshots, which I did and that cleared enough storage up so the server returned to normalcy. Today it happened again even though there are no snapshots. Looking into the datastore, there is the server.vmdk at 50GB and server_1.vmdk at 8TB, as expected, but I don't understand what server_1-000001.vmdk is? Is it some old snapshot file that remained even after all snapshots were removed? I left for lunch wanting to recharge before getting back into it and the server is up and running upon my return but I imagine it will happen again soon since the datastore is maxed out at 9TB.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you post a screenshot of a full folder listing?
-------------------------------------------------------------------------------------------------------------------------------------------------------------
Although I am a VMware employee I contribute to VMware Communities voluntarily (ie. not in any official capacity)
VMware Training & Certification blog
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
scott28tt
Per some suggestions I've seen to others in identical situations, I created another snapshot, which made 000002 and then attempted to Delete-All but that has been stuck at 50% for several hours. I can't stop the task or start another. The two snapshot files still exist.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The _00000x File indicates that your VM is running on a Snapshot which means all writes aka "data changes" goes into this files. In a worst case with a lot of changes or over a looooong time the size of the _00000x file can be the same as your origin base -flat.vmdk. This is the reason why your running out of space because 8TB base + XXTB snapshot >= size if datastore.
From you screenshot there are 2 snapshots.
Regards,
Joerg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The snaps of your FTP1.vmdk are already committed and most likely its working on FTP1_1. To check if its do something i use esxtop on ESXi shell and take a look to the device/hba/lun stats of my storage. I do this before i commit a large snap to see the difference in CMD/s and Write MB/s. With the size of my snap i can calculate how long it would take.
Regards,
Joerg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Snapshots got removed but the files 00000x did not and they take up more space than is available so the guest cannot start up and operate. I read somewhere to not remove those files manually so how do I get rid of them, if the snapshots were already removed but the files remain?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I read somewhere to not remove those files manually so how do I get rid of them, ...
Caution: There are only a few situations where snapshot files are not deleted automatically, so that should only be considered after verifying that they are indeed orphaned!
To get an overview, please attach the VM's configuration (.vmx) file to your next reply, and post another file listing, but this time from the command line, i.e. the output of the command ls -lisa
The command's output will show the provisioned as well as the currently used disk space for each file.
André
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
vmx attached.
[root@localhost:/vmfs/volumes/5ee0d4c7-3fb9a1c4-80ba-001e673428cd/FTP1] ls -lisa
total 9736992960
2244 128 drwxr-xr-x 1 root root 77824 Sep 12 07:01 .
4 1024 drwxr-xr-t 1 root root 73728 Jun 24 22:10 ..
205524228 0 -rw-r--r-- 1 root root 13 Sep 12 07:01 FTP1-aux.xml
4197636 52428800 -rw------- 1 root root 53687091200 Sep 11 22:14 FTP1-flat.vmdk
37752068 64 -rw------- 1 root root 8684 Sep 11 22:14 FTP1.nvram
8391940 0 -rw------- 1 root root 499 Sep 10 17:58 FTP1.vmdk
12586244 0 -rw-r--r-- 1 root root 77 Sep 11 22:20 FTP1.vmsd
3332 0 -rwxr-xr-x 1 root root 3583 Sep 11 22:20 FTP1.vmx
75500804 0 -rw------- 1 root root 3444 Jun 25 19:36 FTP1.vmxf
138415364 1094621184 -rw------- 1 root root 1136152346624 Sep 12 07:01 FTP1_1-000001-sesparse.vmdk
142609668 0 -rw------- 1 root root 311 Sep 10 20:30 FTP1_1-000001.vmdk
197135620 1024 -rw------- 1 root root 34634465280 Sep 12 07:01 FTP1_1-000002-sesparse.vmdk
201329924 0 -rw------- 1 root root 318 Sep 11 22:19 FTP1_1-000002.vmdk
100666628 8589934592 -rw------- 1 root root 8796093022208 Sep 12 07:01 FTP1_1-flat.vmdk
104860932 0 -rw------- 1 root root 452 Sep 11 22:20 FTP1_1.vmdk
29363460 1024 -rw-r--r-- 1 root root 493823 Jun 25 04:29 vmware-1.log
67112196 2048 -rw-r--r-- 1 root root 1224285 Jul 1 17:33 vmware-2.log
121638148 1024 -rw-r--r-- 1 root root 372676 Jul 1 18:27 vmware-3.log
159386884 2048 -rw-r--r-- 1 root root 1470715 Sep 11 22:14 vmware.log
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The snapshot for the 50GB disk has been removed, but the snapshot for the second virtual disk still exists, and is active (as you can see in the configuration file).
The snapshot has a size of ~1TB which may require some time (hours) to be deleted, depending on your physical disk subsystem.
Since the base disks have been created as Thick Provisioned, and the VM is powered off, deleting the snapshot should work even with low free disk space on the datastore.
Can you confirm that the Delete Snapshot task already ended successfully?
André
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It was taking hours so the Web UI timed out and did not have task result listed in "recent tasks" after that. I don't know if they should still be there.
But the snapshots are gone:

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Never trust the Snapshot Manager!
Please follow the steps in https://kb.vmware.com/s/article/2146185 to see whether a remove snapshot deletion/consolidation task is still running.
André
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I took yet another snapshot with guest shut down and then started a consolidation task. It's been 24 hours and I'm at 6% completion so this will take two weeks before I can give an update. Seems excessive, no? I swear my hard drives are not solar powered. Although even if they were, it's summer time in California so they should have enough juice.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Wow, that really seems to be too slow.
Do you see any Controller/HDD related messages in the ESXi host's vmkernel.log?
What type of datastore is this, i.e. is it create on a single local disk, on a RAID LUN, or on shared storage? With a local disk, or a RAID LUN that operates in write-trough mode speed may be slow, but again, what you see is not what I would expect (except that the shown percentage will not count all the way up to 100%).
André
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is on a Supermicro server with RAID of SAS drives. I did not experience any slowness on the guest.
The only "errors" or "warnings" in the log is this which I do not understand:
2020-09-17T15:29:09.774Z cpu0:2097711)ScsiDeviceIO: 3435: Cmd(0x459abcfac7c0) 0x4d, CmdSN 0x5420 from world 2098973 to dev "naa.600605b0038bf1f026738f15a6be2836" failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x20 0x0.
Attached are some screenshots of storage performance. The process is at 15% so I'm moving up in the world 😄
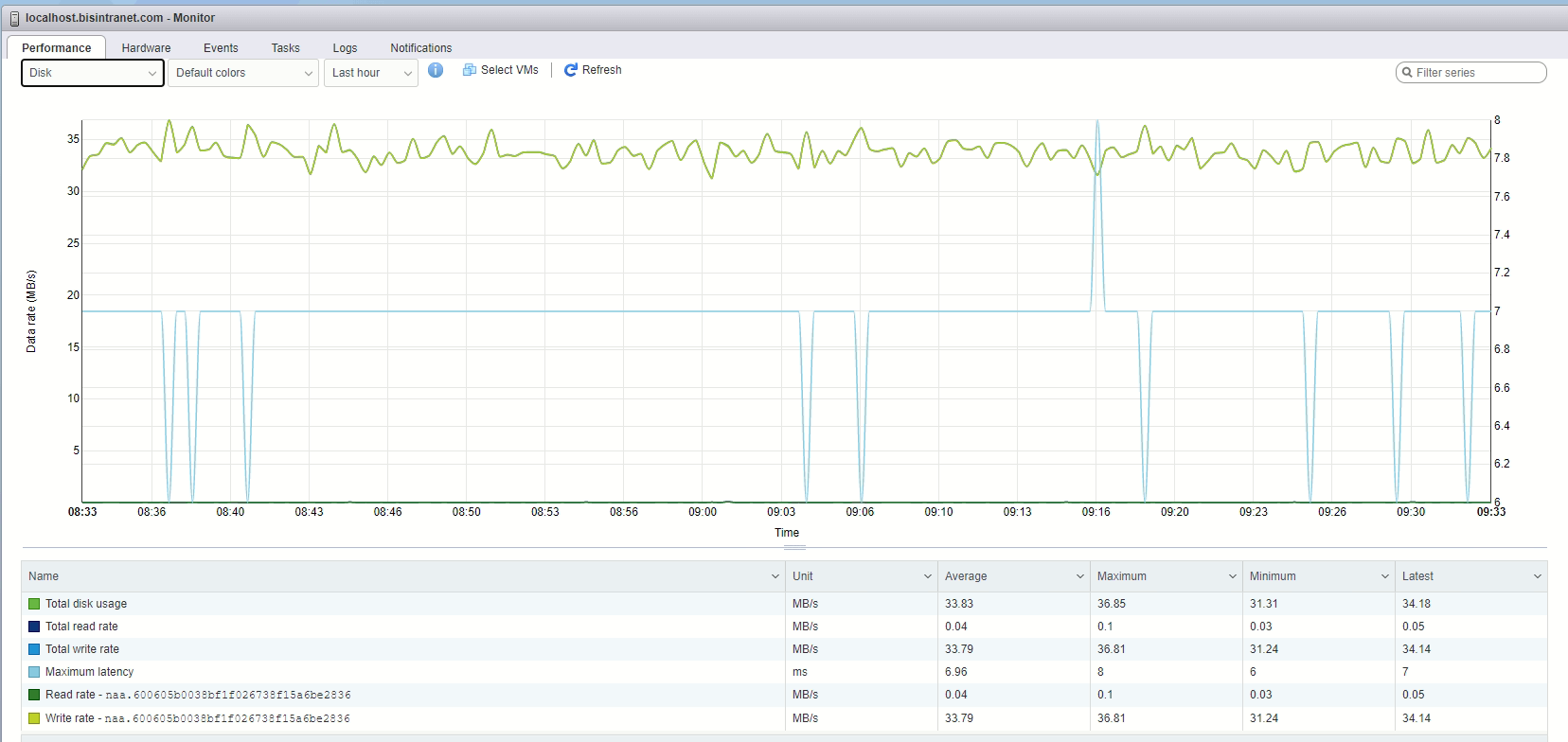{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Took about a week but it finished and removed the snapshot files. Hardware performance seems on par for the guest so I don't know why consolidation was taking so incredibly long. Gotta remember not to use the snapshot feature again.