- VMware Technology Network
- :
- Cloud & SDDC
- :
- ESXi
- :
- ESXi Discussions
- :
- System Board 8 Memory - Uncorrectable ECC
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
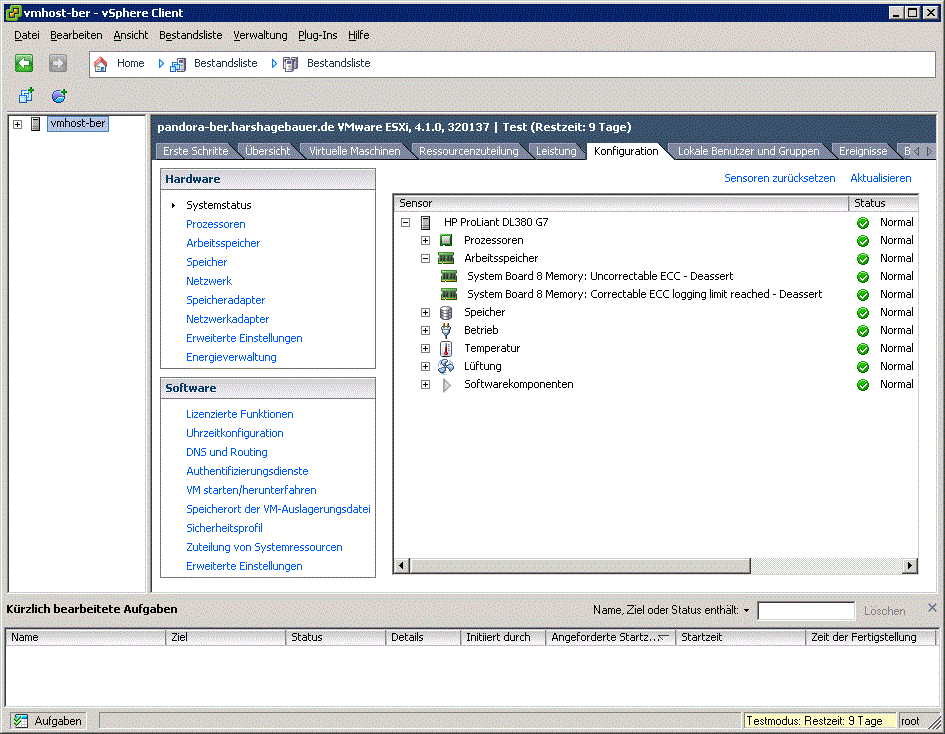
We setup ESXi 4.1 with latest patches applied on a brand new HP DL380 G7 with latest FW and latest ESXi Offline Bundle, which shows the ECC problem you can see from the attached screenshot.
We opened a case at HP and they told us that none of the HP diganostics (IML + Survey) shows any problems at all. We also changed memory modules on bank 8 which didn't change anything. HP said that this seems to be a problem of ESXi displaying wrong information.
Is there any known problem with ESXi 4.1 showing invalid information?
Do you have any suggestions?
Thanks.
{kind=link}
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It seems to me that there is no hardware problem here and ESXi is working correctly.
The sensor name is "System Board 8 Memory - Uncorrectable ECC", it's status is "deassert" (i.e. not asserted) and hence the health condition is "normal". If the hardware in the server detects uncorrectable ECC events, the sensor status will change to "assert" or "failure asserted" or similar and the health would then be degraded or failed (that is, if the server was still running).
Attached is a screenshot of some other sensors reported in this way, in this case fro,m a PowerEdge.
Hope that helps.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would run an extended Memtest to make sure.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Already done.
No problem found.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you have a current VMware Support contract I would give VMware a call.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Problem is Essential is only available with subscription and not with basic support so calling VMware for 300$ and getting said that it is a HP thing is not the best option.
Cheers.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do you have power saving mode enabled in the BIOS. I can't remember the wording but try full power.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We had changed that to custom -> OS controlled.
I will try if this changes anything.
Cheers
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good bet that is the problem.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Tried that but problem persists.
To get sure it is nothing with the installation I reinstalled vanilla ESXi from scratch.
Same errors are shown in VSphere Client after installation.
Ran another Survey and all RAM modules are operating correctly and neither correctable nore
uncorrectable ECC errors have been logged during operation.
Found in the revision history of latest ESXi patches some problems were fixed
for ESXi showing some wrong fan and temperatur values however nothing mentioned
regarding any wrong information about ECC state.
Cheers.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You haven't used the HP version of ESXi to install. When you use the HP version CIM is enabled. When you use the generic install and use the offline bundle I am pretty sure you must enable OEM Cim providers. Also make sure that you have upgraded the firmware to the level as shown for ESXi 4.1. Just applying the latest may go beyond what is supported for ESXi. I would pay some special attention to ILO firmware.
Try looking at the web system page for the ILO interface. It could confirm or deny HPs claim that RAM is OK.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi.
Thanks again for you suggestions but all this we alredy tried.
1.) Installing vanilla ESXi 4.1 -> problem present
2.) Adding HP's latest offline bundle -> problem present (It adds some additinal indicators like Disk)
3.) Applying all patches (currently 2 which are mentioned on the VMware website)
4.) Checking all diagnostics HP offers (Survey, IML, ILO)
Running out of ides.
Cheers.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can I just clarify the problem here.. the screenshot shows badly for me but it looks like it says "deassert" after it followed by status: Normal?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
J1mbo schrieb:
Can I just clarify the problem here.. the screenshot shows badly for me but it looks like it says "deassert" after it followed by status: Normal?
Yes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It seems to me that there is no hardware problem here and ESXi is working correctly.
The sensor name is "System Board 8 Memory - Uncorrectable ECC", it's status is "deassert" (i.e. not asserted) and hence the health condition is "normal". If the hardware in the server detects uncorrectable ECC events, the sensor status will change to "assert" or "failure asserted" or similar and the health would then be degraded or failed (that is, if the server was still running).
Attached is a screenshot of some other sensors reported in this way, in this case fro,m a PowerEdge.
Hope that helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
OK
So you say that the shown screenshot does not indicate an error condition at all?
Maybe we simply interprete it wrong.
Can anybody verify that this is shown similar on other installations?
And why it is referreing to System Board 8 Memory?
Cheers.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
exactly.....
The uncorrectable ECC is just a sensor instance. Its deasserted and hence the reading is shown as normal(Green) . If ever something fails on the device monitored by this sensor , then the state of this sensor changes to an assert. That is when the reading becomes red and lets you know it is faulty.
So there is nothing to worry about as long as the reading is green. I have seen the same on a variety of hardware.
In order to confirm, do the following steps:
1. Install a WBEM client (wbemcli a command line tool, apt-get wbemcli on ubuntu) on a linux machine.
2. Do a CIM query to CIM_Sensor: Copy the contents to a file:
wbemcli ein -noverify 'https://root:<password>@<hostname>:5989/root/cimv2:CIM_Sensor' ElementName,HealthState | tee SensorList.txt
3. Open SensorList.txt and search for ECC
<snip>
Host:5989/root/cimv2:OMC_DiscreteSensor.DeviceID="201.0.32.1"
</snip>
4. If the health state above has a value 5 , you have nothing to worry about.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The command in step 2 of previous comment should be:
wbemcli ei -nl -noverify 'https://root:<password>@<hostname>:5989/root/cimv2:CIM_Sensor' ElementName,HealthState | tee SensorList.txt
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi.
Sorry for giving feedback so late, but the customer did not have a linux box and I did not find a live CD which includes wbemcli so I had to setup a linux machine first and install the wbem package.
I can confirm that health state of the ECC sensors is 5 so from what I have learned no reason to worry about. It seems that I was fooled by a somewhat missleading way this information is beeing displayed.
Thanks again to all for the usefull tips to track down the problem.
I will try to assign points accordingly.
Cheers.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Did you get anywhere with this please?
I have a DL380 G7 that is showing a "warning" with System Board 8 showing "deassert".
Despite power cycling the server and clearing the IML logs in the iLo, the server shows a clean bill of health yet vsphere won't reset the "warning" status on the host hardware tab.
I can clear the alarm, but that isn't really the point.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Could you show me the screenshot