- VMware Technology Network
- :
- Cloud & SDDC
- :
- vSphere vNetwork
- :
- vSphere™ vNetwork Discussions
- :
- Re: dvPort Group Odd Behaviour
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
dvPort Group Odd Behaviour
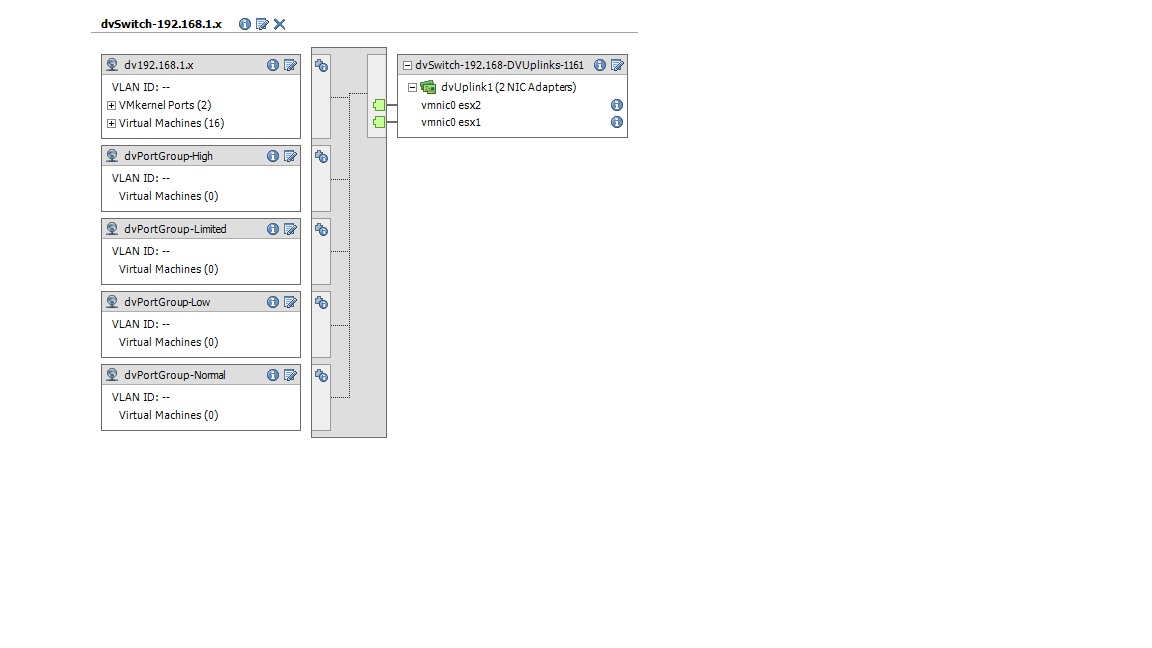
Long story short, I have migrated the network configuration of a couple of hosts we have to dvSwitches. That seemed to go fine. Now however we are looking to implement network I/O control. I have enabled network I/O control and defined user defined network resource pools. I then create new dvPort groups and associate each of the resource pools to the newly created dvPorts. Finally I move 1 of the VM's from the existing default dvPort group that we created that every VM resides in on this host to one of the new dvPort groups with I/O control enabled. Once moved the VM is able to communicate across the network fine however it no longer can communicate to the default gateway.
I'm left scratching my head. Anyone have any idea's? We are not using any type of VLANID's. The two hosts are connected to a single simple switch.
Its just a play environment and its really not that complicated of a design. I don't get how the VM's can communicate to other things with in the same subnet (even machines not on the ESX host) but when it comes to trying to get to the gateway and beyond it simply doesnt.
If you move the VM back to the original dvPort group all network communication picks back up.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
A small update to this. It looks like having multiple port groups isnt the problem. Its when I assign the actual resource pool to the port group the behaviour begins to happen. The minute I take the resource pool configuration off the dvPort group communication flows correctly. Still stumped.... anyone have an idea or direction I can go in?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
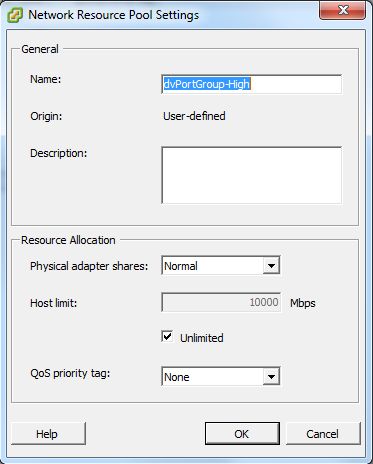
You mentioned that you are not using VLANs, but have you set any of the Network Resource Pool priority settings?
The Ethernet 802.1p priority fields (3 bits) are carried inside the 802.1Q tag, and it might be that your physical switch will drop any tagged Q frames even if the VLAN id is set to 0.
Check the "QoS priority tag" for your Resource pool.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sadly no Qos priority tags defined.
If this were the case, and the physical switch was dropping the packets, I would think that the VM's wouldnt be able to talk with anything outside the virtual infrastructure. As the machine connects to a gig switch and from there goes to the router. But this isnt the case. The VM's can talk to other things on the network (which goes through other physical switches), just when trying to get to the router it fails.
Am I correct in that statement or is my understanding of things wrong?
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is really very odd. You are correct that if the 802.1p tag would make the traffic unavailable then it would affect communication with everything else, and not just the default gateway.
So the situation is that if you have the VM on a portgroup without Resource Allocation you can reach the gateway, but with this enable then communication stops? If you have a ping -t running will it just stop in the middle?
You have only a single vmnic connected to the Distributed Switch from each host?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You are correct, if I have the vm connected to a port group with no resource group associated to it and continously ping the gateway it works fine. The minute I apply the resource group setting the pings just stop mid way. If I cancel out of the ping and attempt to restart the ping to the gateway it says destination host unreachable almost as if suddenly the vSwitch's arp table doesnt understand were to go to get to the gateway (only a guess at this point).
If I am pinging something like a machine (regardless of another VM or physical box) pings dont stop and communication works fine.
And yes I only have a single nic connected to the vswitch from each host.
I wasnt aware that there should be any modifications to the packets when resource group allocation is set is there?
I would hope not. QoS yes, but for the host to simply start to prioritize packets flowing in / out the vswitch based on port i woudlnt think it would need to modify the data going through it outbound, or does it?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
woodycollins wrote:
If I cancel out of the ping and attempt to restart the ping to the gateway it says destination host unreachable almost as if suddenly the vSwitch's arp table doesnt understand were to go to get to the gateway (only a guess at this point).
The vSwitch is only a layer two device and have no knowledge of the relation between IP and MAC. The MAC forwarding table is also quite easy, since it knows the MAC for all internal VMs and by that know that everything else is on the outside.
Are you using a Windows VM?
Could you run something like:
ipconfig
arp -d
ping GATEWAY
arp -a
Switch to Resource network pool
ping GATEWAY
arp -a
I wasnt aware that there should be any modifications to the packets when resource group allocation is set is there?
I would hope not. QoS yes, but for the host to simply start to prioritize packets flowing in / out the vswitch based on port i woudlnt think it would need to modify the data going through it outbound, or does it?
If setting any priority with the "QoS" on the Distributed vSwitch it must do some manipulation on the frames. The QoS information is carried in three bits called 802.1p, which is included inside the 4 Byte 802.1Q tag, which is added to each frame. I am thinking of writing some blog post about this in the near future.
I did also confirm myself that if setting the "QoS" to none will not do any manipulation of the frames.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The boxes I have are all linux based VM's but if need be I can load a windows box. Here is the output of the commands you asked me to run using linux instead of windows (hopefully it tells you what you were looking for).
Before:
eth0 Link encap:Ethernet HWaddr 00:50:56:AF:B4:9E
inet addr:192.168.1.98 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::250:56ff:feaf:b49e/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:220418 errors:0 dropped:0 overruns:0 frame:0
TX packets:3910 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:4316021 (4.1 MiB) TX bytes:314840 (307.4 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:20 errors:0 dropped:0 overruns:0 frame:0
TX packets:20 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1616 (1.5 KiB) TX bytes:1616 (1.5 KiB)
virbr0 Link encap:Ethernet HWaddr 52:54:00:AE:94:77
inet addr:192.168.122.1 Bcast:192.168.122.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:864 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:41767 (40.7 KiB)
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_seq=1 ttl=64 time=1.53 ms
64 bytes from 192.168.1.1: icmp_seq=2 ttl=64 time=0.412 ms
64 bytes from 192.168.1.1: icmp_seq=3 ttl=64 time=0.369 ms
64 bytes from 192.168.1.1: icmp_seq=4 ttl=64 time=0.438 ms
64 bytes from 192.168.1.1: icmp_seq=5 ttl=64 time=0.511 ms
64 bytes from 192.168.1.1: icmp_seq=6 ttl=64 time=0.364 ms
64 bytes from 192.168.1.1: icmp_seq=7 ttl=64 time=0.375 ms
64 bytes from 192.168.1.1: icmp_seq=8 ttl=64 time=0.386 ms
64 bytes from 192.168.1.1: icmp_seq=9 ttl=64 time=0.371 ms
64 bytes from 192.168.1.1: icmp_seq=10 ttl=64 time=0.370 ms
--- 192.168.1.1 ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 9002ms
rtt min/avg/max/mdev = 0.364/0.513/1.534/0.343 ms
? (192.168.1.32) at 00:50:56:af:c8:05 [ether] on eth0
? (192.168.1.1) at 00:22:6b:3b:01:ec [ether] on eth0
After:
eth0 Link encap:Ethernet HWaddr 00:50:56:AF:B4:9E
inet addr:192.168.1.98 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::250:56ff:feaf:b49e/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:220132 errors:0 dropped:0 overruns:0 frame:0
TX packets:3886 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:4297371 (4.0 MiB) TX bytes:313181 (305.8 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:12 errors:0 dropped:0 overruns:0 frame:0
TX packets:12 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:720 (720.0 b) TX bytes:720 (720.0 b)
virbr0 Link encap:Ethernet HWaddr 52:54:00:AE:94:77
inet addr:192.168.122.1 Bcast:192.168.122.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:863 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:41721 (40.7 KiB)
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
From 192.168.1.98 icmp_seq=2 Destination Host Unreachable
From 192.168.1.98 icmp_seq=3 Destination Host Unreachable
From 192.168.1.98 icmp_seq=4 Destination Host Unreachable
From 192.168.1.98 icmp_seq=6 Destination Host Unreachable
From 192.168.1.98 icmp_seq=7 Destination Host Unreachable
From 192.168.1.98 icmp_seq=8 Destination Host Unreachable
From 192.168.1.98 icmp_seq=9 Destination Host Unreachable
From 192.168.1.98 icmp_seq=10 Destination Host Unreachable
--- 192.168.1.1 ping statistics ---
10 packets transmitted, 0 received, +8 errors, 100% packet loss, time 19002ms
pipe 3
? (192.168.1.32) at 00:50:56:af:c8:05 [ether] on eth0
? (192.168.1.1) at 00:22:6b:3b:01:ec [ether] on eth0
Let me know if you need me to load a windows box up and run the same commands.
You don't think its a bug in the build im using of 5.1 do you?
Esx: Build 5.1.0 Build 941893
vCenter: 5.1.0 Build 947673
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Could you also run the command (I belive it is the same in Linux) :
arp -a
before and after the adding resource pool setting.
woodycollins wrote:
You don't think its a bug in the build im using of 5.1 do you?
It could be possible, but I have not heard of any known issues with the Network Resource Pools in 5.1. The problem is however very strange and it is hard to see what could possible change from the perspective of reaching your default gateway.