- VMware Technology Network
- :
- Cloud & SDDC
- :
- vSphere Storage Appliance
- :
- vSphere™ Storage Discussions
- :
- Incorrect "Used Storage" reported - ESX 5.5
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Incorrect "Used Storage" reported - ESX 5.5
Hello everybody,
We have a strange problem since we migrated some hosts in ESX 5.5...
On our cluster, 14 hosts are in 5.5 and 2 are still in 5.1 (we stopped the migration when we stumbled on this problem... Here it is :
Our biggests vm (> 500 Gb provisionned) are reporting incorrect "Used Storage" (and "Not-Shared Storage btw). These vms are in thin provisionning.
The datastores they are located in are all in VMFS 5.54 (this problem is on all our datastores, not just only one)
If we perform a vmotion to an ESX 5.1 host, this problem disappear, but it's back with a vmotion back to 5.5...
Our storage is provided by 2 datacore hosts, San-Symphony V 9.0 PSP3.
I attached 2 screenshots showing my problem...
anybody here already experienced this problem ?
Thanks, and best wishes to you all,
V-
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi ,
This seems to indicate a problem only with Esxi 5.5 or may be a Bug with ESXi 5.5 ie Since you migrate it back to ESXi 5.1 and it works good.
did you report this to VMware and have a Support Ticket number by any chance.?
Thanks,
Avinash
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Avinash, and thanks for your time.
We filled a request with Vmware (SR 13413795112) and the support told me that SS-V is not compatible with ESX 5.5. I am only half convinced with this explanation as the ESX 5.1 are working well. I read (i hope thoroughly) the change log but it has no mention about a change in the way ESX 5.5 is reporting (or asking ?) the thin provisionning data...
Moreover, we discovered that we had another issue with ESX 5.5, concerning the io limit of a VM...On a ESX 5.1, the limits are correctly respected (i.e. io limit of 500, we'll see a straight line at 500 io/s under heavy load). But in ESX 5.5, the limit is like a third of what we configured (if we configure 500 iops, we got like 165 iops) and this is clearly not a straight line. It vary between 60 and 180 iops...
Regards,
Vincent.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Vincent,
Thank you for your update and reply. I am trying to reproduce this problem at my test environment, I will definitely let you know if I get any updates from my end on this situation.
Thanks,
Avinash
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Vincent,
Both you and VMware are correct in regards to this situation, firstly your storage is not supported for the ESXi 5.5, But you were right with the thought the incorrect "used storage" does seem to be a Bug , I was able to reproduce the problem with a different
storage model and the same issue. I will provide you with more details once i have update
Thanks,
Avinash
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Avinash,
thanks for your time and tests ! If you want more information or have me do some more testing, please feel free to ask. Have you had the time to check with our io limit problem ?
Thanks,
Vincent.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I can confirm the same thing is happening with a EMC VNX5300 as the storage and vCenter 5.5b.
Thanks,
David
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi,
we got the same problem on VNX 5300 and vsphere 5.5 too.
On 1 esx if a vm got an IO Limit it will create a hudge kernel latency (KAVG/WR) on the ESX, if we remove all the IO limit everything is ok.
We got a case open with the VMware support. (No problem on vpshere 5.1)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am having a similar issue as well on 5.5 u1. Nimble storage is showing a free space of 5tb on my lun, VMware is reporting something less. the discrepancy seems to be with the used space. Used space on vsphere is over 9 tb while used space showing on Nimble is showing just over 5 ( taking advantage of compression etc)
this is not happening on Netapp using nfs.
does anyone have any updates on this? Also what happens if we just let VMware report 0 free space? If there is free space on the LUN will VMware still lock and suspend all vms on the volume when it reaches 0 ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am also having this issue on 5.5 (not u1) latest build version of ESXi 5.5.0 build 1746018. As an example, we have a thin provisioned VM that is allocated 550GB, actual usage when looking through Storage Views shows the correct usage of about 500GB. The summary page of the virtual machine shows 88.93GB Used Storage, Not Shared shows the same value, Provisioned showing 550GB. We are currently using EMC storage which is supported by 5.5, and the drivers / firmware / flexcode are all on a supported level.
I'm currently getting VMware to investigate this issue, and I'll let you know what they come back with.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
any update on this by chance? I made another volume and had the same exact results.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Has anyone been able to find a solution to this? We are noticing the same issue on vSphere 5.5 as well. If we perform a storage vMotion to another data store on the same SAN, it correctly updates the "Used Storage" amount. It seems to be an issue at the host level since it shows the issue when you connect directly to a host as well as through vCenter. We are using a SAN different than previous posters, but it is on the supported HCL.
To some extent, it appears that storage DRS looks at the "Used Storage" when calculating stats for moves, since I now see it failing storage vMotions periodically due to insufficient disk space. The total Free Space per data store appears to be correct regardless of this bug.
Thank You!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi All,
Apologies for missing to update the Thread, well VMware confirmed that is as per design and are trying to make it better, The vpxa agent on each host schedules a thread to monitor the free space on the datastore every five minutes; if the change in value is greater than 100 MB, it re-syncs this value on the vCenter Server. There is a KB Article that is published.
--Avinash
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As I said to you in MP, the "Get-Datastore" method worked for me, but one question remains. As I understand, this problem should have disappeared maximum 5 minutes after its apparation since vpxa is refreshing these data every 5 minutes. For us, the problem was still there, weeks after it appeared.
Am I missing something here ?
Regards,
-Vincent.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Well, this story is not at the end yet...
The problem is still here, only on the vsphere client, it vanished on the web client.
As you can see here, the Used space is correct (1.05 TB)

But it is not correct here (19 GB)

Moreover, the values returned by PowerCli is buggy too :

Uncommited is 1262 GB (1356126488716 KB) but it should be 205 GB
And on the vm informations, the "UsedSpaceGB" is ~ 19GB, should be ~1.05TB

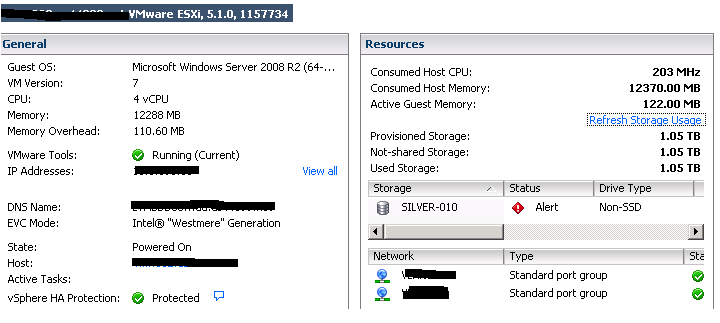{kind=link}
{kind=link}
Some thoughts :
1/ It seems to be buggy only on huge VM ( > 1TB disks). Other seems fine
2/ How the web client os calculating the good infos ? Is there a new method on PowerCli to retrieve these numbers ?
-Vincent
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi All,
VMware is aware of this problem and working on it. if you have the same situation in your environment please have a SR raised with VMware to get an update or status on the same.
Thanks,
Avinash
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Any updates ?
We have the same problem(s) with a VNX5300, ESXi 5.5u1
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Here is what I can tell you as I have the same issue with a VNX 5300, and I am completely disgusted with VMware's attitude of dealing with it.
The issue is stale entries in the hostd cache. Rebooting the hosts or restarting the management agents do not fix the issue. I have been assured by VMware that no data is at risk it is purely a reporting function.
The only current fix is a storage vmotion of the affected VM's.
I chased VMware after they closed my support case with a status of resolved after having done very little!
They said they have a number of calls about the issue and it is a known bug being dealt with by their engineering team. I then discovered they have known about the issue since February 2014. I then challenged as to why there was no KB article and they have now begun writing an internal KB which will be published in a few days...
I will update when I have more...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for your answer,
I reported this problem to VMWare january 6th of this year.
The way VMWare is handling this issue is indeed very disappointing.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Yes it is very disappointing...
Also I forgot to put in my post that the engineering team have given a provisional date (Although not in writing...) of October being the fix date!