- VMware Technology Network
- :
- Cloud & SDDC
- :
- vSphere Storage Appliance
- :
- vSphere™ Storage Discussions
- :
- Re: I am out of ideas - High Latency on a LUN - on...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am out of ideas - High Latency on a LUN - on hosts with no VMs
This has been quite an eventful week with not much sleep.
At the moment we are in a situation where no one knows what else we can do. Let me first explain what happened.
We introduced an additional blade to our infrastructure. It was load-tested for 10 days, all stable and nice. Monday then that host disappears from the vCenter.
The host itself is still up, just cannot connect to vCenter / Client. VMs are up too so that was a bonus. After hours with VMware support they basically gave up and we had not choice but to bounce the host - well, to add insult to the injury, HA didn't work and did not fail the VMs over.
Problem in scenarios like that is that while the (disconnected) host is still in vCenter - the VMs are too - which are disconnected but showing as powered on - which they are not. So you cannot even migrate them (like you can with powered off VMs).
Next "solution" was to remove the host from vCenter. At this stage we were finally able to add the VMs back to the inventory using other hosts.
Of course there were some corruptions / broken VMs / Fricked up VMDK descriptor files and the list (and hours) go on.
We initially thouight that was it - far from it ... we continued to see latencies on all datastores / hosts of 250k-700k ms ... yepp .. 700.000 ms ...
A power-on operation (or even adding VMs back into the inventory) took up to 30 minutes / VM.
Anyway ... we obviously opened tickets with the storage vendor as well and they of course blamed VMware .. I actually managed to get both in a phone conference, VMware and Storage vendor with VMware confirming yet again a storage issue. Three days later still no result.
At some point we had a hunch - all these VMs, which were affected, were also migrated using DRS (when you least need it) which bombed out when the host crashed the second time (before we finally pulled the blade).
Locks - our guess .. So some VMs we expected to be the culprit, were rebooted .. and ola ... latency gone.
No one can explain what happens, why that "fixed" some issues, but heh - we were happy ...
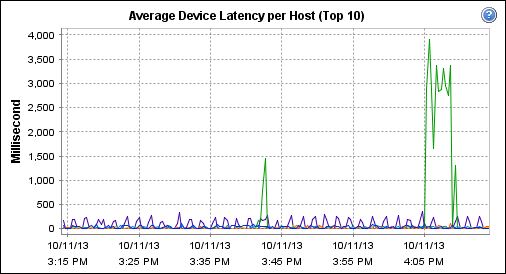
Well now the weirdest thing ... and to actually finally get to the point, we have two hosts .. EMPTY hosts .. no VMs, showing the same sort of device latency on ONE particular datastore. As soon as you put the hosts back into maintenance mode, the latency goes down to nothing
Attached shows where the host was taken out of maintenance mode and put back in again.
Now VMkernel logs show some SCSI aborts and yes, this is likely due to storage issues which we may still have - however, how can the only hosts showing now a latency with no VMs on it when they are out of maintenance mode, but look fine when in maintenance mode and all other hosts with the VMs running, are fine ?
Now we are in a blame loop - storage vendor blames vmware, vmware blames storage vendor.
VMware Supports also just shrugs when I try to get an explanation how a rebooted VM can cause the latency to calm down as it surely shouldn't make a difference if the storage back end is to be blamed ....
So I hope someone here can give me some pointers, because right now we are out of ideas (and clearly so are the vendors)
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Evening,
You got a fun one there... A few questions first:
additional blade to our infrastructure - Was it a gen 7 or gen 8 HP Blade? If yes then I know what caused the initial issue and how to solve it. Look into the emulex parts on your blade they caused the issue and will continue to do it. Random nics going down without correct failover.
->
Locks - our guess .. So some VMs we expected to be the culprit, were rebooted .. and ola ... latency gone.
No one can explain what happens, why that "fixed" some issues, but heh - we were happy ...
-> This is a fun issue I have seen these where the descriptors to clean up but to create that much latency is odd. I am afraid you took the correct process reboot neither side will admit or really diagnose the issue when the solution is easy like a reboot... (I once had a Kernel panic in ESXi and support said how long to re-install and I said about 30 minutes... their response was who cares about root cause we have been on the phone for 2 hours just reinstall. Not to blame vmware support it was the quickest way to get into a good state again)
Now VMkernel logs show some SCSI aborts and yes, this is likely due to storage issues which we may still have - however, how can the only hosts showing now a latency with no VMs on it when they are out of maintenance mode, but look fine when in maintenance mode and all other hosts with the VMs running, are fine ?
-> If a host has no vm's and no locks running the only difference between a host on maint mode and not is HA. If you are running HA I guess it could be the HA datastore lock files (assuming your running 5.0+) causing the latency.
No matter you have a bad situation that should not happen. I would do the following:
1. Send the logs from your chassis back plane to the vendor to make sure nothing is boinked up
2. Reboot each ESXi host in an orderly fashion
3. Reboot the storage controllers in an orderly fashion
This will essentially clear out any odd locks. If it does not solve the problem I am afraid you have to press the vendors more...
Also if you provide more info on version of ESXi and storage/ blade type it might help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The hosts are on U1 Build 702118 and yes it is Gen 7 or 8 .. I will have to check that as it has been removed for now - but I am intrigued - what would the fix be because at the moment we are reluctant to put it back into production.
As for a solution - a week now down the line and we are still in the middle of a blame war, but I THINK I have fixed the issue for now. Oh and a storage processor reboot is planned for next week already. We still have the odd issue, with standby luns missing, some hosts missing some LUNs etc., which is hopefully solved by the reboots.
But the high latency was the main concern of course, but that I think is fixed at the moment.
How ? Well it doesn't look like it was storage after all (regardless of VMware insisting on it up until now).
Like I said - the hosts behave fine when in maintenance mode and only one LUN was affected.
Host in cluster = High latency on LUN X
Host rebuilt and put back in cluster = High latency on LUN X
Put host in maintenance mode = Latency gone.
Take host out of maintenance mode = High latency on LUN X
Remove host from cluster = Latency gone
Remove host from vCenter = Latency gone
So it smelt fishy really and if it was the storage, then why is the issue gone in the conditions above? I am still waiting for the answers, anyway, what is involved in the conditions where the latency is high ? The vCenter / HA agent.
Checked HA and bang - the LUN in question was used for HA heartbeating so yes, your guess was also spot on (a shame I only read it today, could have saved me a night of tinkering).
I then remembered that HA didn't work when the host crashed / powercycled so a theory is, the heartbeat folder was locked even though it wasn't ... or wasn't even though it was supposed to.
Either way - when change the HA datastore heartbeat to another LUN - the latency issue disappeared ...
So it clearly was a VMware issue after all, and not an issue on the storage itself. It really is frustrating that VMware support still has no idea and still blames the storage vendor and vice versa ...
The only option is obviously Business Critical Support with onsite support - but we cannot really afford the $50k / year (or whatever that costs nowadays) - so we are at the mercy of VMware and other vendors involved.
Either way - I'd appreciate any further hints regarding the Gen 7 / 8 blades
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Morning,
The hosts are on U1 Build 702118 and yes it is Gen 7 or 8 .. I will have to check that as it has been removed for now - but I am intrigued - what would the fix be because at the moment we are reluctant to put it back into production.
-> We ran into this issue where blades nic's would be online but refuse to send traffic. It's a bug in the emulex code in our case and after two months emulex via HP was unable to release a driver to fix the issue. It just kept happening we would install a beta driver provided by HP and it would happen again at random times. We solved the issue by replacing the emulex cards with broadcom. This does present an issue because the broadcom cards are unable to do FCoE so it's a trade off... I know this I will never buy emulex again their support teams and VMware and HP are horrible. VMware in my case was very helpful but could not solve the issue.
As for a solution - a week now down the line and we are still in the middle of a blame war, but I THINK I have fixed the issue for now. Oh and a storage processor reboot is planned for next week already. We still have the odd issue, with standby luns missing, some hosts missing some LUNs etc., which is hopefully solved by the reboots.
-> These issues are critical your storage vendor should have some solutions for these problems. I would 100% reboot asap but also if you are missing LUN's then your vendor needs to root cause that issue. If your array is acting so oddly I would not trust any data on it and do a reboot of controllers asap.
Host in cluster = High latency on LUN X
Host rebuilt and put back in cluster = High latency on LUN X
Put host in maintenance mode = Latency gone.
Take host out of maintenance mode = High latency on LUN X
Remove host from cluster = Latency gone
Remove host from vCenter = Latency gone
->Odd question... What about a physical host (non-vmware) with LUN X given your above statement about missing lun's etc... your array is in a very bad place.
So it smelt fishy really and if it was the storage, then why is the issue gone in the conditions above?
-> My guess because when it's out of maint mode and in the cluster HA tries to write to data store and the data store is really boinked up. When not in cluster no HA writting to datastore so no metrics... do this test take out of cluster and then run a vm workload I bet the latency is high.
I am still waiting for the answers, anyway, what is involved in the conditions where the latency is high ? The vCenter / HA agent.
So it clearly was a VMware issue after all, and not an issue on the storage itself.
->I'll be honest that I don't agree I still think it's a issue with the storage array... Try a vm work load on the lun X without HA enabled and see how it is... is that works ok then it is HA datastore heartbeats
The only option is obviously Business Critical Support with onsite support - but we cannot really afford the $50k / year (or whatever that costs nowadays) - so we are at the mercy of VMware and other vendors involved.
->Yeah given your solution is almost all HP I would look into escalating that agreement before the vmware one.
I agree that vendor fun is a pain in the butt.... There is no real answer here I end up solving it myself most of the time. Sorry I did not respond sooner but glad I could help. I really would press the storage vendor for root cause on storage issues... I doubt you will get anything but end of the day you need to know how to avoid it from happening again. Also get emulex cards gone if you can.
Thanks,
J
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So I suppose you guys using IP Storage (ISCSI ?) - because we only use the onboard NICs (Emulex indeed) for network traffic. Our storage - which seems to be the issue here - is using QLogic HBAs. We never actually had problems where the nics refused to send traffic. I now forwarded VMware my findings yet again and asked for an explanation and how we can avoid this in the future .. Still waiting for a reply so it will be interesting to see what the outcome is / will be.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Morning,
->So I suppose you guys using IP Storage (ISCSI ?) - because we only use the onboard NICs (Emulex indeed) for network traffic. Our storage - which seems to be the issue here - is using QLogic HBAs. We never actually had problems where the nics refused to send traffic. I now forwarded VMware my findings yet again and asked for an explanation and how we can avoid this in the future .. Still waiting for a reply so it will be interesting to see what the outcome is / will be.
- We are 100% FC SAN based storage using HBA's as well the original outage issue was caused by the emulex see below:
We introduced an additional blade to our infrastructure. It was load-tested for 10 days, all stable and nice. Monday then that host disappears from the vCenter.
The host itself is still up, just cannot connect to vCenter / Client. VMs are up too so that was a bonus. After hours with VMware support they basically gave up and we had not choice but to bounce the host - well, to add insult to the injury, HA didn't work and did not fail the VMs over.
-> This was caused by emulex which started the mess... now the mess seems to be a storage issue to me... just my two cents:
Remediation:
1. To avoid network outage remove emulex and replace with broadcom
2. To resolve current latency issues press storage vendor and reboot controllers asap
Just my two cents on this issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Michael, did you ever get an answer for this issue from a while ago? We seem to be having the same exact issue with our environment. Gen 7 HP server, Compellent storage, QLogic HBA's.
I have turned off HA for now for VMware.
VMware support pointed back at the HP server, but all 3 systems are showing the same latency issue, so they then pointed back to the Compellent SAN.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Chad
I have seen a very similar case last year and was able to relate it to a VMFS-problem.
Would you mind and tell me the size of the datastores you use and the VMFS-version ?
A good test to see wether its the same issue would be to post the result of
vmkfstools -p 0 name-flat.vmdk > mapping.txt
Run that command against the flat.vmdk of your slowest virtual disk.
________________________________________________
Do you need support with a VMFS recovery problem ? - send a message via skype "sanbarrow"
I do not support Workstation 16 at this time ...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is what I get...
Mapping for file TESTVMDK.vmdk (505 bytes in size):
[ 0: 505] --> [VMFS -- LVID:50c75412-191793a2-0743-00215acb1ce2/50c75412-dd165a5e-d47f-00215acb1ce2/1:( 66829312 --> 66829817)]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Poor example - a text descriptor vmdk will always be in one piece.
Run the command against a large flat.vmdk
________________________________________________
Do you need support with a VMFS recovery problem ? - send a message via skype "sanbarrow"
I do not support Workstation 16 at this time ...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Chad
this vmdk seems fine to me - it does NOT display the issue that I observed in the case I had in mind.
I dont have ANY reason to assume something is wrong with the VMFS-volume.
________________________________________________
Do you need support with a VMFS recovery problem ? - send a message via skype "sanbarrow"
I do not support Workstation 16 at this time ...