- VMware Technology Network
- :
- Cloud & SDDC
- :
- VMware vSphere
- :
- VMware vSphere™ Discussions
- :
- Re: Stretched-Clusters, VM->Host affinity and Reso...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I wonder if anyone can help me on this one.
We've spent a long time planning the implementation of Resource-Pools, and have digested all there is to consume on the pitfalls and gotchas of the unintended consequences they bring. We even wrote in-depth powershell scripts which query the VM's in the resource pools, calculate the number of vCPU's present and work out the correct ratio of shares to allocate to the pool to avoid this. It all seems sound. (off topic - but looks like scalable shares may make all that redundant!!).
One thing I've never been able to solve though, is Resource-Pool management on stretched-cluster scenarios that use site-local vm-host affinity DRS rules.
e.g:
a cluster has 8 hosts over 2 sites - 4 hosts in each site. DRS VM->Host affinity rules exist (using vm groups and host groups) to work around active-active/passive storage limitations. i.e. vm's could run from non-site local storage, but there is a large performance penalty - the rules are therefore in place to keep VM's at their preferred site. However, there is always the (likely) potential of an imbalance of VM's (more importantly, vCPU's) across sites. Because of this, and that fact that shares are a percentage of the total cluster capacity - not site capacity, there is the potential for the number of shares allocated to a resource group to exceed the physical capacity of a site (i.e. 50% of the cluster).
Does anyone know how Resource Pool scheduling deals with this when it see's it? It obviously cant allocate more than it has, but what happens to the other competing resource groups?
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
TL;DR: In short don't worry about the RP structure, the actually allocation targets will flow to the VMs based on their location and the relative priority with the DRS group. it depends on you which VMs to place in which site\vm-group. If you distributed the VMs in an unbalanced manner, you will end up with contention, just because DRS cannot move the VMs to a host with enough resources.
Interesting question and fascinating to see your observation that RPs are not site-aware. But luckily for you, this lack of site-awareness will not impact your design. The reason why is that the distribution of resources is done on a consumer-based mapping. (it's all in the cluster deep dive book btw).
So let's start from the beginning, shares only matter when contention occurs, if you have no contention, resources are distributed to VMs that request it. I.e. resource allocation = demand.
Now when contention occurs, that where the resource pools claim their stake of the cluster resources and distribute it across its siblings (VMs inside the RP). Andreas already pointed out the scalable shares deep dive.
To answer your question we need to take a look at how a cluster resource pool structure works inside a distributed system. A cluster accumulates all the resources of all the hosts in the cluster and pools this at the root level (cluster). This becomes the cluster capacity. When it divides (divvy) the resources, it does this based on entitlement. Entitlement is a combination of resource allocation settings (R, L, S), VM activity, and the activity in the cluster. It calculates this relative priority. We introduced relative priority because we understand that not all workload is 100% all of the time. This sets us apart from every other scheduler out there, this makes it so cool, but also difficult to understand.
To give an example, when I have 3 VMs, each identically configured, it will be entitled to 33% of the resources. But this calculation is only true if all 3 VMs are active at the same time and active on the same resources at the same rate. We call this a worst-case scenario allocation, but this situation helps to explain how shares work. In reality, this won't happen often. So in a more likely scenario, one VM is active for 80%, one for 40%, and one is idling. Now that means that there are two VMs competing for resources. If there are enough resources to divvy amongst the two VMs, one VM will get the resources based on its 80% activity, the other one 40%. If there aren't enough resources, it will be divided. How? the resources are shared amongst the two competing VMs with the active shares. Now this means that they are now competing at a 50% rate. Each is entitled to 50% of the resources, but because one VM is only active for 40%, it will take the resources it needs and the remaining resources can be consumed by the VM which is active for 80%. The actual allocation of resources is done by the host-local CPU and memory scheduler. Based on the entitlement of the VM, time is allocated for the VM to consume those resources.
And this is the key to mapping a distributed hierarchy (resource pools) across hosts within the cluster. When a resource pool structure is created, a tree structure is created and the VMs are the leaves. When a VM is placed on a host, then that leave should hang from something and only that part of the tree is replicated to that host. So if you have 2 VMs each in its own RP pool attached to the root. If each VM is placed on a separate host, one host will have one part of the tree replicated to it, the other host, the other part. Once this is done, DRS will calculate the entitlement of the VMs and send over the information. In this story, you can replace your sites with these two hosts.
The trick to understanding this is the relative entitlement and the possibilities for DRS to actually find a host where the VM can allocate the resources it is entitled to. And that's where you have to play a role in it, as you have introduced a constraint. If a VM is entitled to X, the host-local scheduler attempts to provide those resources, but if contention occurs, the host local scheduler might not be able to provide those resources. Thus DRS attempts to find another distribution of VMs in such a way that the resources flow to the VMs that are entitled to it. With the VM groups aligned to site structure, you've instructed DRS to only move the VMs around the four hosts in each site, and thus there is a limited number of moves to make, a restriction of possible placement combinations. The resource pool structure and the entitlement calculation will be based on the actual placement of the VMs, and thus it depends on you which VMs to place in which site\vm-group. If you distributed the VMs in an unbalanced manner, you will end up with contention, just because DRS cannot move the VMs to a host with enough resources.
In short, don't worry about the RP structure, the actual allocation targets will flow to the VMs based on their location and the relative priority with the DRS group.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Greetings,
I cannot really answer your question, but I want to comment on what you did and ask some questions back ...
Regarding your scripting work for adjusting resource pools I want to make you aware of a new feature in vSphere 7.0 called "scalable shares". It is supposed to solve exactly the problem that you now solve by scripting and continuously adjusting the resource pools' shares. Read about it here: vSphere 7 DRS Scalable Shares Deep Dive - frankdenneman.nl and here: vSphere 7 and DRS Scalable Shares, how are they calculated? | Yellow Bricks
Regarding your stretched cluster setup and assigning VMs to sites with DRS rules I'm curious to know why exactly you are doing this. vSAN stretched clusters use a feature called "Read locality" that ensures that their storage read accesses are always served from the site that they are running on (to avoid reads crossing the site-interlink). Storage write access will always cross the site-interlink, because each objects need to be stored on both sites (unless you use PFTT=0 to have a VM stored on one site only). Read about read locality here: Read Locality in vSAN Stretched Clusters | vSAN Stretched Cluster Guide | VMware. Of course there are other reasons why you might want to pin your VMs to one site, but avoiding site-interlink traffic is not one of them.
As I said I cannot answer your question how resource pools are affected by DRS affinity rules, but let's try to pull in the gurus on this subject: FDenneman01 and depping Can you comment, Frank or Duncan?
- Andreas
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
TL;DR: In short don't worry about the RP structure, the actually allocation targets will flow to the VMs based on their location and the relative priority with the DRS group. it depends on you which VMs to place in which site\vm-group. If you distributed the VMs in an unbalanced manner, you will end up with contention, just because DRS cannot move the VMs to a host with enough resources.
Interesting question and fascinating to see your observation that RPs are not site-aware. But luckily for you, this lack of site-awareness will not impact your design. The reason why is that the distribution of resources is done on a consumer-based mapping. (it's all in the cluster deep dive book btw).
So let's start from the beginning, shares only matter when contention occurs, if you have no contention, resources are distributed to VMs that request it. I.e. resource allocation = demand.
Now when contention occurs, that where the resource pools claim their stake of the cluster resources and distribute it across its siblings (VMs inside the RP). Andreas already pointed out the scalable shares deep dive.
To answer your question we need to take a look at how a cluster resource pool structure works inside a distributed system. A cluster accumulates all the resources of all the hosts in the cluster and pools this at the root level (cluster). This becomes the cluster capacity. When it divides (divvy) the resources, it does this based on entitlement. Entitlement is a combination of resource allocation settings (R, L, S), VM activity, and the activity in the cluster. It calculates this relative priority. We introduced relative priority because we understand that not all workload is 100% all of the time. This sets us apart from every other scheduler out there, this makes it so cool, but also difficult to understand.
To give an example, when I have 3 VMs, each identically configured, it will be entitled to 33% of the resources. But this calculation is only true if all 3 VMs are active at the same time and active on the same resources at the same rate. We call this a worst-case scenario allocation, but this situation helps to explain how shares work. In reality, this won't happen often. So in a more likely scenario, one VM is active for 80%, one for 40%, and one is idling. Now that means that there are two VMs competing for resources. If there are enough resources to divvy amongst the two VMs, one VM will get the resources based on its 80% activity, the other one 40%. If there aren't enough resources, it will be divided. How? the resources are shared amongst the two competing VMs with the active shares. Now this means that they are now competing at a 50% rate. Each is entitled to 50% of the resources, but because one VM is only active for 40%, it will take the resources it needs and the remaining resources can be consumed by the VM which is active for 80%. The actual allocation of resources is done by the host-local CPU and memory scheduler. Based on the entitlement of the VM, time is allocated for the VM to consume those resources.
And this is the key to mapping a distributed hierarchy (resource pools) across hosts within the cluster. When a resource pool structure is created, a tree structure is created and the VMs are the leaves. When a VM is placed on a host, then that leave should hang from something and only that part of the tree is replicated to that host. So if you have 2 VMs each in its own RP pool attached to the root. If each VM is placed on a separate host, one host will have one part of the tree replicated to it, the other host, the other part. Once this is done, DRS will calculate the entitlement of the VMs and send over the information. In this story, you can replace your sites with these two hosts.
The trick to understanding this is the relative entitlement and the possibilities for DRS to actually find a host where the VM can allocate the resources it is entitled to. And that's where you have to play a role in it, as you have introduced a constraint. If a VM is entitled to X, the host-local scheduler attempts to provide those resources, but if contention occurs, the host local scheduler might not be able to provide those resources. Thus DRS attempts to find another distribution of VMs in such a way that the resources flow to the VMs that are entitled to it. With the VM groups aligned to site structure, you've instructed DRS to only move the VMs around the four hosts in each site, and thus there is a limited number of moves to make, a restriction of possible placement combinations. The resource pool structure and the entitlement calculation will be based on the actual placement of the VMs, and thus it depends on you which VMs to place in which site\vm-group. If you distributed the VMs in an unbalanced manner, you will end up with contention, just because DRS cannot move the VMs to a host with enough resources.
In short, don't worry about the RP structure, the actual allocation targets will flow to the VMs based on their location and the relative priority with the DRS group.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Andreas,
Thanks for the links, indeed it was Frank and Duncan's blogs which lead me to ask my question, as I may need to rethink/delay our implementation until we've moved to vSphere7, which should only be a few months away.
To answer your question, our storage is on IBM v7000 Hyperswapped storage, which is a synchronously replicated stretched cluster storage solution. The host connections are active/active-passive, so they can see all paths as active, but if the storage system witnesses too many writes to the non-preferred copy, then it will flip the replication direction over to the other site. This has a time delay penalty associated, so we need to avoid it by pinning VM's to hosts based at the site with the primary copies. Its a mega pain, and limits the design, but it does work well.
I could solve the problem by configuring a cluster with only site-local compute - but having a stretched cluster and cross-site storage allows easy site fault tolerance without SRM complexity (or cost). It's just this confusion over respools that's troubling me.
Hopefully the attached picture will explain it better.
As you can see, the allocation percentage of the main respool - "Live-DC1" - will exceed the physical cores and ram for that site because of the imbalance. In fact, the allocation would need to be exactly 50:50 for this not to be the case for any stretched cluster where vm's are pinned to a site.
So a general understanding of how resource pools cater for stretched clusters would be really useful.
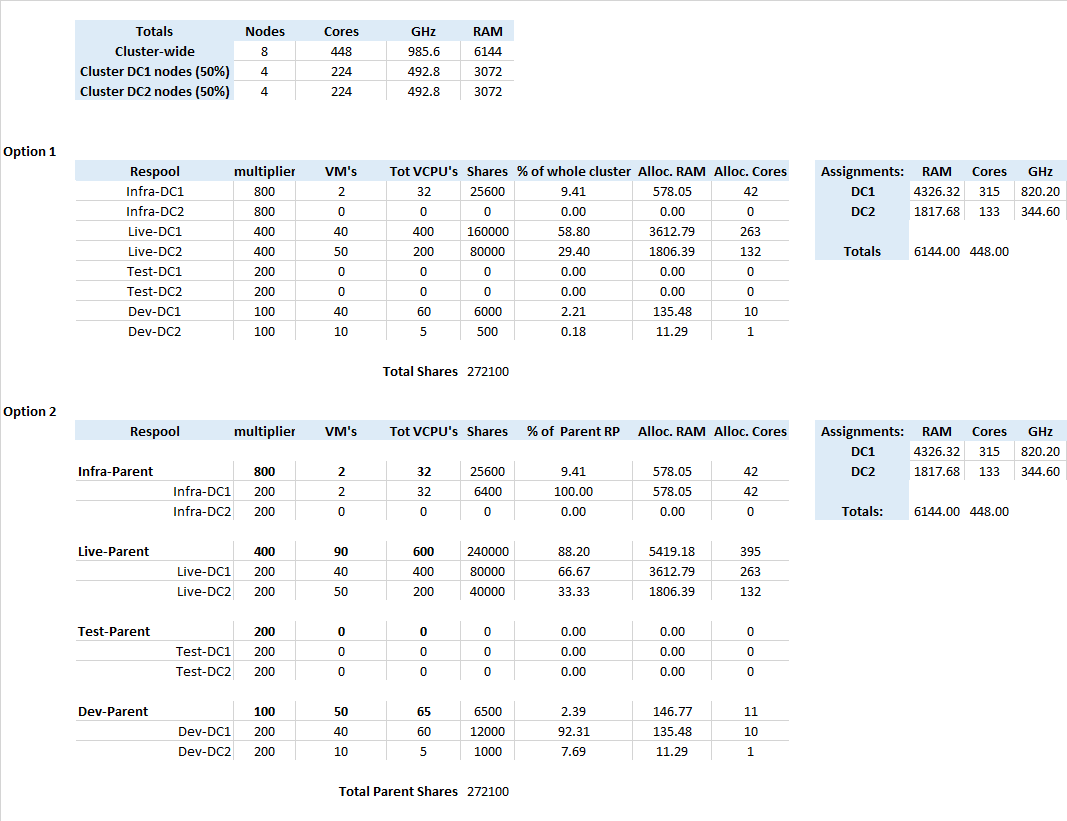{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks FDenneman01, that all makes sense, I have a background in AIX/Solaris fair share scheduling so understand most of what you're saying. Scheduling is all about fairness, not making sure it will work - if its oversubscribed it will still break whatever. As you say, the art is in understanding/predicting contention scenario behavior and its effect/relation to all workloads.
If I understand correctly then, the actual 'worst case' values are calculated on clusterwide capacity, but the actual running values will depend on the relative values of competing workloads within a DRS group of compute. All we are really doing within a resource pool is weighting the siblings within the scheduler (which is why hierarchy is very important).
I may well get this cluster deep dive book if it covers all this content.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ah okay, when reading "stretched cluster" I was automatically thinking "vSAN stretched cluster" although you never mentioned vSAN. Sorry for the confusion.
BTW I definitely recommend getting Frank's Deep dive book. I have a paper copy next to my bed, now I actually need to find the time to read it before falling asleep 🙂