- VMware Technology Network
- :
- Cloud & SDDC
- :
- VMware vSphere
- :
- VMware vSphere™ Discussions
- :
- High CPU IO WAIT after VM migration
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
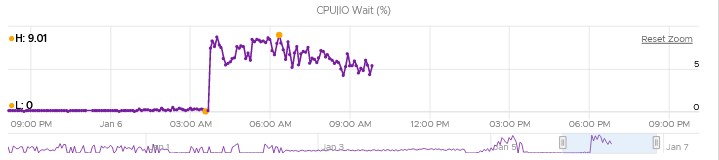
High CPU IO WAIT after VM migration
Hello everyone
I have a very strange issue and that is when DRS (or even manually) migrates some virtual machines to other hosts, the amount CPU IO Wait metric becomes high for that machines. so I have to migrate that machine again and the metric become low. as far as I know this metric is related to a poor performance storage system or if cd rom is attached to the VM but all of my hosts are connected to the same storage systems. Is there any parameter that should I check?
Can any one help me in this regard?
Thank you

{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
CPU IO Wait is somewhat of a misnomer, it is basically wait - idle - swap wait for vCPU worlds (VMWAIT - SWPWT in esxtop terms). It's basically anything a vCPU / VMM can block on. That could be _non guest IO_ that has to happen like snapshot meta data updates but also resources that are held like a lock / mutex etc. which ultimately might take longer because of under performing storage but it doesn't have to be.
Sadly it is pretty hard to exactly identify what the vCPUs are blocking on and why without detailed debug logs (e.g. stats vmx, schedtraces, custom vprobes), hence why it probably makes more sense to eliminate possible caused in a methodological fashion. Also, just because the hosts share the storage, they don't share all of the fiber nor the IO devices / HBAs.
Questions:
- Is this only happening to a single / limited set of VM / Host (or combination of)? If it is a set, what do those have in common? What is different? (older / newer vHW? older / newer ESXi build? different virtual devices configures etc.)
- Is it only happening when vMotioning to a host? Does it still happen after a full power cycle of the VM? (so not a guest-OS reboot)
- Is the VM running of a snapshot?
- Can you check per vCPU stats by expanding the VM's GID in esxtop?
- When you say "migrate again", do you mean back to the source host or to any other host, even hosts that would have shown the same symptom if migrated to from the original source? I.e. can you identify the _act_ of vMotion, corrected for souce and destination, as the "on / off" switch for that behavior?
- If yes, does this also happen when suspending / resuming a VM? What about FSR?
- When you vMotion a VM to the host, once the task has completed, are there any messages / warnings / errors in the VM's vmware.log or the hosts vmkernel.log that are otherwise not seen when there is no "CPU IO Wait"?