- VMware Technology Network
- :
- Cloud & SDDC
- :
- vSAN
- :
- VMware vSAN Discussions
- :
- Re: Write latency and network errors
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Write latency and network errors
I'm trying to troubleshoot a write performance issue and noticed that there is VSCSI write latency. We have a 4 node cluster with dual 10GB links on brocade vdx switches. The only thing I noticed is that there are some out of order rx errors in vsan observer during the time of the latency. Has anyone seen this issue before? I'm attaching a screen shot from observer.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For the X710 (X71x & 72x) disabling LRO / TSO have resolved a lot of the issues encountered in the past.
We are aware of the LRO/TSO errors and the firmware/driver version recommendations for the X710's and have already been through all of those settings.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Also all of our hardware is on the HCL and has matching drivers/firmware.
I actually posted another thread specific to my issue at All-Flash vSAN Latency & Network Discards (Switching Recommendations)
I just wanted to give the poster here some reference in case they are seeing the same thing we are seeing.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks LeslieBNS9. I believe we are experiencing similar causation.
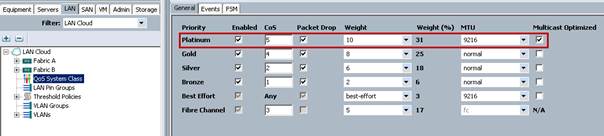
Instead of uplinking our UCS servers directly to switches first they connect to the Fabric Interconnects 6248s, which then uplink to Nexus 7010s via (2) 40GE vPCs. The Fabric Interconnects are discarding packets as evidenced by "show queuing interface" on all active vSAN interfaces. The manner in which we have vmnics situated in VMware (Active/Standby) Fabric B is effectively dedicated to VSAN traffic, and the cluster is idle so not a bandwidth issue or even contention, rather the FI's scrawny buffer assigned to custome QoS System Classes in UCS not able to handle bursts. We have QoS configured per the Cisco VSAN Reference doc. Platinum CoS is assigned qos-group 2, which only has a queue/buffer size of 22720! NXOS in the UCS FIs is read-only so this is not configurable.
I will probably disable Platinum QoS System Class and assigning VSAN vNICs to Best Effort so we can at least increase the available queue size to 150720
Ethernet1/1 queuing information:
TX Queuing
qos-group sched-type oper-bandwidth
0 WRR 3 (Best Effort)
1 WRR 17 (FCoE)
2 WRR 31 (VSAN)
3 WRR 25 (VM)
4 WRR 18 (vMotion)
5 WRR 6 (Mgmt)
RX Queuing
qos-group 0
q-size: 150720, HW MTU: 1500 (1500 configured)
drop-type: drop, xon: 0, xoff: 150720
qos-group 1
q-size: 79360, HW MTU: 2158 (2158 configured)
drop-type: no-drop, xon: 20480, xoff: 40320
qos-group 2
q-size: 22720, HW MTU: 1500 (1500 configured)
drop-type: drop, xon: 0, xoff: 22720
Statistics:
Pkts received over the port : 256270856
Ucast pkts sent to the cross-bar : 187972399
Mcast pkts sent to the cross-bar : 63629024
Ucast pkts received from the cross-bar : 1897117447
Pkts sent to the port : 2433368432
Pkts discarded on ingress : 4669433
Per-priority-pause status : Rx (Inactive), Tx (Inactive)
Egress Buffers were verified to be congested during large file copy:
show hardware internal carmel asic 0 registers match .*STA.*frh.* | i eg
The following command reveals congestion on the egress (reference😞
nap-FI6248-VSAN-B(nxos)# show hardware internal carmel asic 0 registers match .*STA.*frh.* | i eg
Slot 0 Carmel 0 register contents:
Register Name | Offset | Value
car_bm_STA_frh_eg_addr_0 | 0x50340 | 0x1
car_bm_STA_frh_eg_addr_1 | 0x52340 | 0
car_bm_STA_frh_eg_addr_2 | 0x54340 | 0
car_bm_STA_frh_eg_addr_3 | 0x56340 | 0
car_bm_STA_frh_eg_addr_4 | 0x58340 | 0
car_bm_STA_frh_eg_addr_5 | 0x5a340 | 0
car_bm_STA_frh_eg_addr_6 | 0x5c340 | 0
car_bm_STA_frh_eg_addr_7 | 0x5e340 | 0
nap-FI6248-VSAN-B(nxos)# show hardware internal carmel asic 0 registers match .*STA.*frh.* | i eg
Slot 0 Carmel 0 register contents:
Register Name | Offset | Value
car_bm_STA_frh_eg_addr_0 | 0x50340 | 0x2
car_bm_STA_frh_eg_addr_1 | 0x52340 | 0
car_bm_STA_frh_eg_addr_2 | 0x54340 | 0
car_bm_STA_frh_eg_addr_3 | 0x56340 | 0
car_bm_STA_frh_eg_addr_4 | 0x58340 | 0
car_bm_STA_frh_eg_addr_5 | 0x5a340 | 0
car_bm_STA_frh_eg_addr_6 | 0x5c340 | 0
car_bm_STA_frh_eg_addr_7 | 0x5e340 | 0
nap-FI6248-VSAN-B(nxos)# show hardware internal carmel asic 0 registers match .*STA.*frh.* | i eg
Slot 0 Carmel 0 register contents:
Register Name | Offset | Value
car_bm_STA_frh_eg_addr_0 | 0x50340 | 0
car_bm_STA_frh_eg_addr_1 | 0x52340 | 0
car_bm_STA_frh_eg_addr_2 | 0x54340 | 0
car_bm_STA_frh_eg_addr_3 | 0x56340 | 0x1
car_bm_STA_frh_eg_addr_4 | 0x58340 | 0
car_bm_STA_frh_eg_addr_5 | 0x5a340 | 0
car_bm_STA_frh_eg_addr_6 | 0x5c340 | 0
car_bm_STA_frh_eg_addr_7 | 0x5e340 | 0
I should note we are not seeing discards or drops on any of the 'show interface' counters.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Subscribing. I have same issues.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We're having the same issue on a new 12 node, all flash stretch cluster with raid-5 and encryption. Write latency is very high. We have support tickets open with Dell and VMware. We've done testing with hcibench and SQLIO using different storage policies. Raid 1 is better but still below what we consider acceptable.
The out of order packets were caused by having dual uplinks to two different top of rack switches. We resolved that by changing them active-passive instead of active-active. We'll convert to LACP when we get a chance. Networking is all 10gig with < 1ms latency between hosts and sites. Top of rack switches are Cisco Nexus 5K's and all error counters are clean. Using iPerf from the host shell shows we can easily push greater than 9gbit between hosts and sites with .5 to .6 ms latency.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
LeslieBNS9,
Did you ending up getting a deep buffer switch? We are having the same issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello All,
Same issue we are experiencing. Any update for solution?
My switches Nexus 5548UP, a lot of packets are discarding on the switch ports.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Meanwhile, you can read more and more about packet discards on the switch side in All-Flash vSAN configurations. The cause often seems to be the buffer on the switch side. VMware itself gives little or no information about which switch components to use because they want to be hardware independent and don't prefer a vendor. But in my personal opinion, most Nexus switches are crap for use in vSAN all-flash configurations, especially if they're over 5 years old and have a shared buffer.
However, John Nicholson (Technical Marketing vSAN) recently published a post on Reddit that summarizes some points to keep in mind (but it's his personal opinion and no official statement):
- Don't use Cisco FEX's. Seriously, just don't. Terrible buffers, no port to port capabilities. Even Cisco will telly you not to put storage on them
- Buffers. For a lab that 4MB buffer marvel $1000 special might work but really 12MB is the minimum buffer I wantt o see. IF you want to go nuts I've heard some lovely things about those crazy 6GB buffer StrataDNX DUNE ASIC switches (Even Cisco carries one the Nexus 36xx I think). Dropped frames/packets/re-transmits rapidly slow down storage. That Cisco Nexus 5500 that's 8 years old and has VoQ stuff? Seriously don't try running a heavy database on it!
- It's 2019. STOP BUYING 10Gbps stuff. 25Gbps cost very little more, and 10Gbps switches that can't do 25Gbps are likely 4 year old ASIC's at this point.
- Mind your NIC Driver/Firmware. The vSphere Health team has even started writing online health checks to KB's on a few. Disable the weird PCI-E powersaving if using Intel 5xx series NIC's. It will cause flapping.
- LACP if you use it, use the vDS and do a advanced hash (SRC-DST) to get proper bang/buck. Don't use crappy IP HASH only. No shame in active/passive. simpler to troubleshoot and failure behavior is cleaner.
- TURN ON CDP/LLDP in both directions!
- Only Arista issue I've seen (Was another redditor complaining about vSAN performance actually a while back we helped) was someone who mis-matched his LAG policies/groups/hashes.
Interfaces. TwinAx I like because unlike 10Gbase-T you don't have to worry about interference or termination, they are reasonably priced, and as long as you don't need a long run the passive ones don't cause a lot of comparability issues.
https://www.reddit.com/r/vmware/comments/aumhvj/vsan_switches/
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for answer.
Now we are working on the case with Cisco support. If I summary, they recommend us to apply the following steps:
My issue is huge ingress packet discarding by the switch.
- HOLB Mitigation: Enable VOQ Limit
- HOLB Mitigation: Traffic Classification
After applied the steps, I will inform you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Still it continues, we applied QoS by using ACL, but we couldnt finalize the issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Very similar issue here on an all flash 5 node 6.7u2 cluster. 10gig dedicated interface for vSAN using Cisco 3548 switches.
As others we have high write latency. Just a basic copy of a large file between drives within a VM causes write latency to spoke. We often see the copy start out fast for a few seconds then slow. We see output discards on the switch ports increment and with observer we can see retransmits, duplicate acks, data and out of order packets.
We have also tried using a Cisco 4500x switch but the issues remain, but this doesn't have much more in the way of buffers than the 3548.
I'm looking to get my hands on a 25g switch to test. Has anyone with this issue tried increasing network bandwidth and/or a switch with deeper buffers?
- « Previous
-
- 1
- 2
- Next »