- VMware Technology Network
- :
- Cloud & SDDC
- :
- vSAN
- :
- VMware vSAN Discussions
- :
- Permanent "reduced availability with no rebuild" a...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Permanent "reduced availability with no rebuild" after stretching a cluster
Hello,
I have a really weird situation at hand: I helped a customer expand a local 6-node v7 U2b cluster to an 8 node, then move 4 nodes to another DC, deploy a witness and stretch the cluster.
All went well, created the fault-domains and vSAN started to re-shuffle the data. vSAN Health-check was green but of course, some data needed to be moved around to be policy (PFTT=1) compliant. But all was working well.
It was a lot of data so at 17:30 when we went home, most was done and about 1.5 TB was left to be moved around. But all was green.
The next morning, we noticed a "vSAN object health" alert. Long story short, The 2nd VMDK of 11 VM's (out of many) say "reduced availability with no rebuild". They are all Linux VM's and it's always the 2nd VMDK which is always 1TB or 2TB in size.
Here is the interesting part:
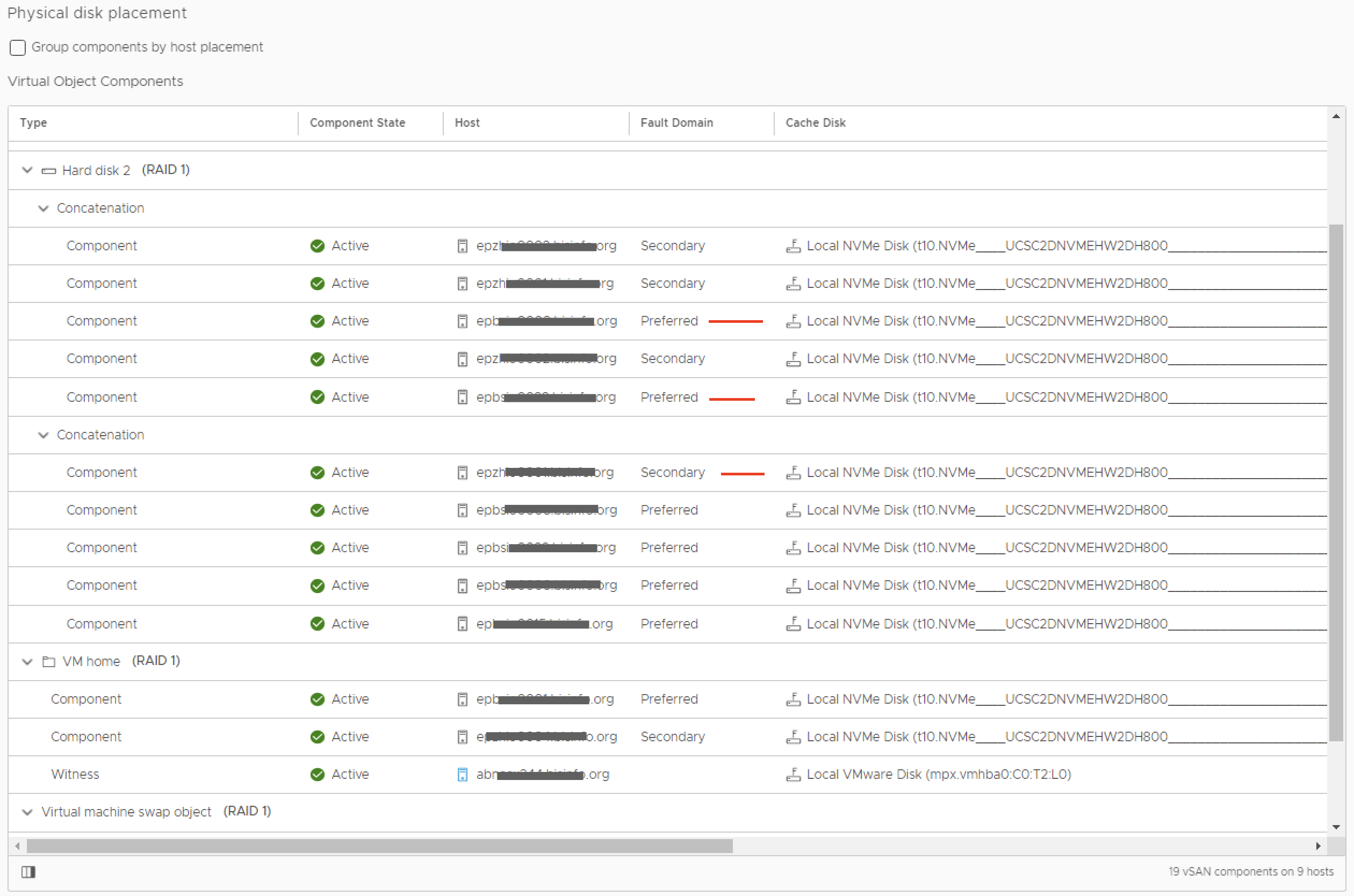
If I go to Cluster -> Monitor -> Virtual Objects, I see the 11 VM's with issues. When unfolding a VM, I see the "Hard disk 2" being in a "reduced availability with no rebuild" state. I then select the checkbox of the "Hard disk 2" and click on "View Placement details". I then see the RAID 1 with two concatenated sections (one for each mirror copy) and in each RAID 1 concat section there are 5 components (large VMDK, gets split up). All components are "green".
In the top concat section (one half of the RAID 1), 4 components are in the preferred Fault Domain (FD) and 1 component is in the preferred.
In the bottom concat section (the other half of the RAID 1), 4 components are in the secondary Fault Domain (FD) and 1 component is in the preferred.
This is wrong of course. Per RAID 1 part, all concatenated components/chunks that form a VMDK should be together in either the preferred or secondary FD, not mixed like this.
So I understand why vSAN complains about these 11 1TB+ VMDK's being "reduced availability with no rebuild" but it does not fix it itself nor does it allow me to fix it. Doing "repair objects immediately" does nothing.
Yesterday, after stretching, all was fine. I suspect that his condition (for these 11 VM's) started after vSAN moved the data around and make all VM's compliant to their "vSAN Default storage policy" of PFTT=1 (there is no SFTT). I have no Idea why vSAN mixed things up like this. But now I'm stuck with it.
The weird thing is, it's always the second, very large VMDK (the first disks are tiny Linux boot disks). All other VM's, large or small, are totally fine. The 112 TB vSAN Datastore is only 26% used so there are oodles of free space free for vSAN to do it's thing. Dedup+Comp is used if that is of any relevance.
I'm thinking of creating a new policy with a PFTT=0, apply it. This should bring all 5 components (in above's example) into the same FD (datacenter essentially). Then assign the normal datastore policy (PFTT=1) which should create a mirror-copy of the VMDK in the other FD and all should be good.
Am I on the right track here?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Update: I created a stretched policy that keeps all the data in the preferred FD and applied it. Sync sync sync and the result is that most components are in the pref. FD but... some are still in second. FD (other datacenter).
Then created a policy that says "stretched cluster but data in second. FD" and applied it. Sync sync sync and the result is that most components are in the second. FD but some are still in pref. FD.
Seriously, vSAN is making a total mess of things. When I apply a policy with all FTT=0 it moves data around and again, and the result is that most components are in one FD but some are still in the other FD.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
"In the top concat section (one half of the RAID 1), 4 components are in the preferred Fault Domain (FD) and 1 component is in the preferred."
"In the bottom concat section (the other half of the RAID 1), 4 components are in the secondary Fault Domain (FD) and 1 component is in the preferred."
What do you mean regarding the 4+1 components per replica?
Is the '1' component Witness component? (shouldn't be as no SFTT as you said)
Is the '1' component a Durability/Delta component? (it should state this in the physical component placement pane)
Did you change the original Storage Policy to be a stretched one as opposed to standard cluster? (under 'Site Disaster Tolerance' field)
Do you have other similar-sized vmdks that appear normal? If so then what else do these 11 Objects have in common? (e.g. all same DOM-Owner or all deployed using a 3rd-party tool etc.)
Can you validate that the vmdks are 1MB-aligned? (Right-click the VM > Edit Settings > Hard disk X > Size is a whole GB number e.g not 1000.32742374823423 GB in size).
Can you validate none of these vmdks are running on snapshots? (check the path of the vmdk, don't just trust snapshot manager reference)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
It's only harddisk / VMDK's and only those that are chopped up into chunks because larger than 256GB. In this case, always the "Hard disk 2" with a size of 1 or 2 TB. These are Ansible deployed VM's and are always the same. The 2nd disk can differ in size though.
No other types of components are affected. They where and are distributed completely normal over both Fault Domains.
The "vSAN Default Storage Policy" has not been modified.
No snapshots.
1-MB Aligned yes, as all are "1 TB , 2 TB"
The Cluster has 32 VM's, most of them having a 1 or 2 or 3 TB "Hard disk 2" and only 11 VMs are affected. They are no different than the others (read my comment about Ansible above).
As a test, I took one of those VM's and storage vMotioned it to a NFS Storage. Then moved it back using the datastore default (which is the unmodified "vSAN Default Storage Policy") and viola, all is good: both RAID-1 "halves" are completely (all concatted components) in either the preferred or non-preferred FD's. So I have a way of fixing this now.
I made a screenshot of one of these funky VM's. It clearly shows some components (marked red) in the wrong fault domain. When I move the VM to NFS and back, all is straightened out.
{kind=link}