- VMware Technology Network
- :
- Cloud & SDDC
- :
- vSAN
- :
- VMware vSAN Discussions
- :
- Re: Non-availability related incompliance
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We're seeing a couple of VMs showing in this state while a proactive rebalance is happening, any ideas what causes it?
VM docs are vague on this (apart from it should not happen)
Non-availability related incompliance: This is a catch all state when none of the other states apply. An object with this state is not compliant with its policy, but is meeting the availability (NumberOfFailuresToTolerate) policy. There is currently no documented case where this state would be applicable.
In the web interface I can see this under the vSAN virtual objects compliance view
VSAN - Number of disk stripes per object
Expected value: 3
Current Value: 2
The web interface also shows that there are 3 stripes for each object (Attached)
Is this safe to ignore as a rebalance happens?
Thanks
Alain
{kind=link}
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Alain,
As my colleague Brian said, this is likely being triggered by 2 stripes of the same LSOM-component on one drive.
That kb article was likely written when this Health checks was initially released - a lot has changed in how resyncs/reconfigs can and do occur, especially in 6.6:
https://storagehub.vmware.com/export_to_pdf/intelligent-rebuilds-in-vsan-6-6
If you want more info you should be looking in the clomd.log of the hosts for the affected Object(s) while this is occurring - probably looking for strings such as:
"CLOMReconfigure: Sending a non-compliant configuration to DOM"
In RVC you might get more info of which disks it is moving how much data off:
> vsan.proactive_rebalance_info <pathToCluster>
My best guess is that it could be moving multiple components (from multiple Objects) around at once with the end-goal of having disk-balance and obviously Storage Policy Compliance and having 2 stripes of the same LSOM-component on the same disk for a time is an intermediary step.
If this is only occurring during Proactive rebalance and is compliant after I wouldn't worry about it - worst case scenario is that if the one drive that 2 stripes reside on failed while it is like this, it would have to resync 2 stripes instead of 1.
Bob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
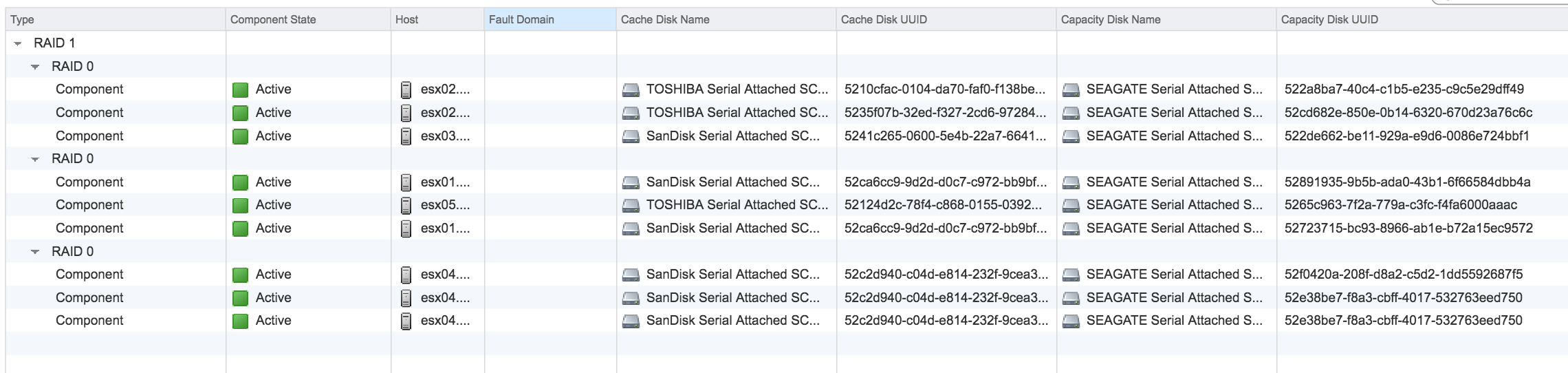
Looking at the screen shot.
2 of the components on the 3rd object are on the same capacity disk.
Does this state go away once the re-balance is complete ?
Can you check the stripes again once re-balance has finished.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Alain,
As my colleague Brian said, this is likely being triggered by 2 stripes of the same LSOM-component on one drive.
That kb article was likely written when this Health checks was initially released - a lot has changed in how resyncs/reconfigs can and do occur, especially in 6.6:
https://storagehub.vmware.com/export_to_pdf/intelligent-rebuilds-in-vsan-6-6
If you want more info you should be looking in the clomd.log of the hosts for the affected Object(s) while this is occurring - probably looking for strings such as:
"CLOMReconfigure: Sending a non-compliant configuration to DOM"
In RVC you might get more info of which disks it is moving how much data off:
> vsan.proactive_rebalance_info <pathToCluster>
My best guess is that it could be moving multiple components (from multiple Objects) around at once with the end-goal of having disk-balance and obviously Storage Policy Compliance and having 2 stripes of the same LSOM-component on the same disk for a time is an intermediary step.
If this is only occurring during Proactive rebalance and is compliant after I wouldn't worry about it - worst case scenario is that if the one drive that 2 stripes reside on failed while it is like this, it would have to resync 2 stripes instead of 1.
Bob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks guys, I'll leave it and see what happens when the rebalance is finished. I looks like they are clearing up.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I had a similar issue withh a customer and it turns out that 2 hosts were recently added to the stretched cluster and were left in MaintenanceMode. Storage policy in use is FTT=1 which means it can only tolerate 1 host failure. In this case there were 2 hosts in MM making a total of 4 fault Domains in the stretched cluster instead of 2
Hence, removing these 2 hosts out of the cluster to a DC level fixed the issue.