- VMware Technology Network
- :
- Cloud & SDDC
- :
- vSAN
- :
- VMware vSAN Discussions
- :
- Latency across vSAN disks
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Latency across vSAN disks
Hi All,
We have upgraded our cluster to 6.7U1. All drivers updated and health passed.
I have a strange issue where my 3 node cluster is displaying a performance hit. We have a database server which actually sits on a host by itself however, persons were complaining of degraded response time. On first look, it seemed like the issue was coming from within the application itself and so we had the application vendor take a look.
The issue started again this morning so i looked again. I am now noticing that VM performance increases across multiple VMs simultaneously.
I've attached a few screenshots to reflect what i'm seeing. Any ideas on where i should start looking at this. Image 1 is the DB server in question and sits on a physical host on its own.
{kind=link}
{kind=link}
{kind=link}
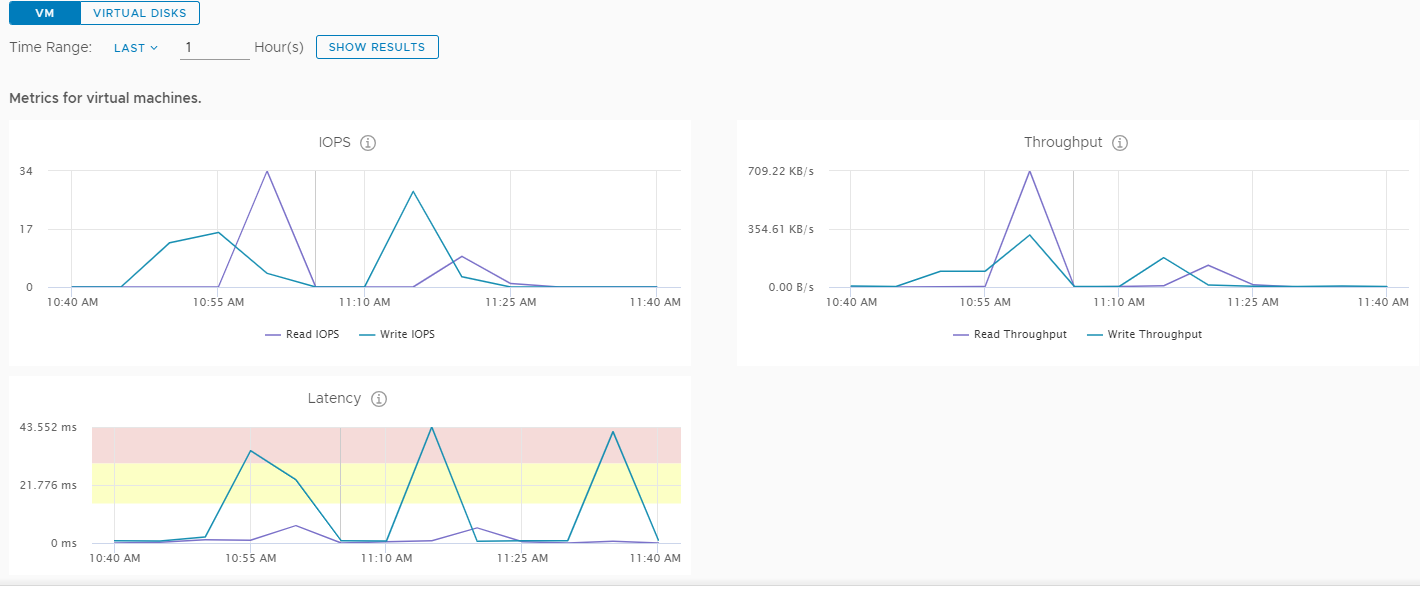{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello cert_junkie
"We have a database server which actually sits on a host by itself however"
A VM running on a host isn't just dependant on the compute resources of that host but the backing storage which in this case is distributed e.g. a VM running on Host3 may have the data-components of its vmdk Objects residing on Host1+Host2 (and with data-components distributed across 4 nodes if using a RAID5 Storage Policy) - thus you can understand how crucial stable and sufficient inter-node network communication is and adequate performance of the backing disks.
Thus, when investigating VM or 'Client' level latency-related performance issues the first step is to determine whether the latency is just occurring at this level (which generally indicates an inter-node network or VM-application issue) or propagated latency from issues at lower layers (e.g. 'vSAN back-end'/Disk/Disk-Group issues). This can be approached in numerous ways including vSphere Performance Graphs, vSAN Observer, 3rd party-tools such as Sexigraf or Grafana (as used by VMware GSS via CEIP data).
If there is Disk/Disk-Group issues you would need to narrow this down further e.g. a single problem Disk/Disk-Group/Controller/Node.
If there is no Disk/Disk-Group latency outside of expected norms for the device type (e.g. SSD vs HDD) then you should start looking at the inter-node communication - e.g. is the cluster flapping, are you getting dropped packets etc. . Specifics may indicate the cause such as are you using 1Gbp/10Gbps networking, multiple links and if so Active/Active or Active/Standby, using etherchannel or LACP and Load-Balancing option in use, and other potential causes such as driver/firmware on NICs updated from what to what.
Note that performance issues are often far from simple to troubleshoot yourself and/or without deep knowledge of the SME so if you have support do consider opening a Support Request sooner rather than later.
Bob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for this Bob, will open a case with support. Was odd that we were running fine under 6.5 U2c and after patching we get this behavior.