- VMware Technology Network
- :
- Cloud & SDDC
- :
- VI 3.X
- :
- VI: VMware ESXi™ 3.5 Discussions
- :
- High hardware interrupt CPU utilization w/local st...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
High hardware interrupt CPU utilization w/local storage
I'm seeing greater than 50% of overall guest CPU utilization coming from hardware interrupts on my system, and I could use some help.
Using Process Explorer on a natively installed Windows 2003 R2 server, I'm seeing regular CPU spikes up to 35% associated with hardware interrupts. After a lot of research and testing/monitoring with SiSoftware Sandra Lite, I have ruled out memory and CPU contention and pinned this down to disk reads and writes causing these hardware interrupts.
My system uses an LSI MegaRaid SAS 8308ELP with battery backed up cache and 8 Seagate ES.2 SATA II drives in a RAID 10 array. Both the VMFS partitions and the Windows partitions were carefully aligned (and it does help). The array pumps out over 450 MB/s on large sequential reads and over 250 MB/s on large sequential writes, so performance is phenomenal, but this is coming at great expence to the CPU by way of these hardware interrupts.
I had a friend with a SAN test his system the same way and he is seeing nothing in the way of CPU utilization associated with hardware interrupts. I have to assume that this has something to do with me using local storage, and some very undesireable behavior of ESX.
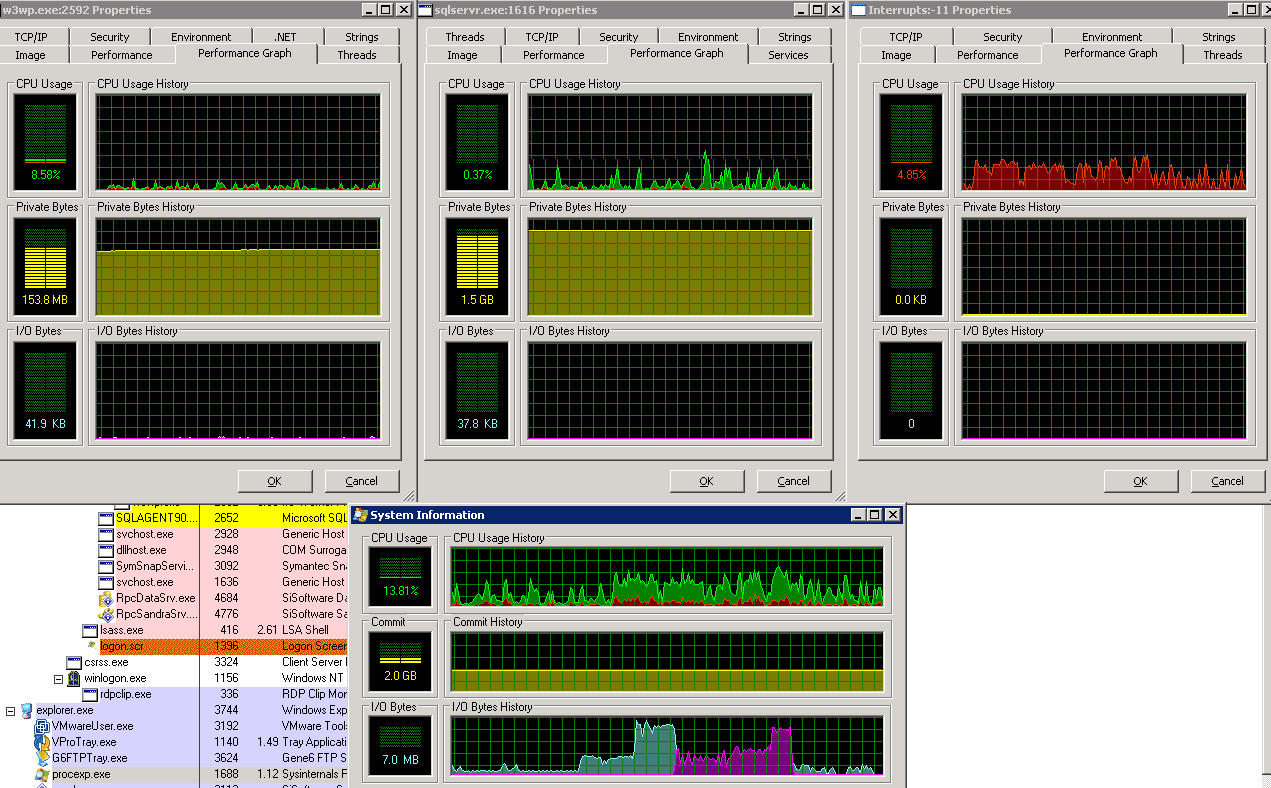
Attached is a screen capture of what Process Explorer shows during the SiSoftware Sandra file system benchmark, which clearly shows the prolonged high hardware interrupt CPU utilization, and it also shows the normal spikey utilization that the server sees under normal operations. The two other windows show the primary non-interrupt CPU users which are MS SQL and a W3WP from IIS, but they pale in comparison. Note that the ESX host has more cores and memory than are currently granted to individual guests, and the other systems running on this box have very nominal utilization overall, however they all show CPU spikes with hardware interrupts on even small reads and writes. The size of the reads and writes however do impact the size of the CPU spikes.
Does anyone have a suggestion for how to approach this. Is this normal with local storage or a bug?
Thanks,
Matt
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Matt, what sort of server / motherboard are you using? Also is it ESX 3.5 or ESX 3i that you're using?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Dave, it's a fully patched ESX 3.5 server, cleanly installed. The server is a SuperMicro 6025B-URV which is on the compatability list along with the RAID card. It has 2 x Intel E5420 procesors (quad 2.5 Ghz each) and currently 8 GB of qualified memory. I was seeing the same thing on another server running 3.x and an unofficially supported Adaptec 2420SA SATA setup (works without tweaking since VMware sees this as a SCSI card), but I'm not concerned about that server at all.
I suppose what would be conclusive is to know if others are also seeing this with local storage during moderate to high disk I/O, with SAS, SCSI or newly supported SATA drives.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The benchmarks thread is mostly a red herring. People running one core and doing a benchmark application while using a software iSCSI initiator are bound to stress their CPU.
I ran the I/O Meter test and watched the both the toal CPU on a seperate 2 CPU guest as well as the hardware interrupt CPU utilization. On the 100% read test, the hardware interrupts were running 20% of 5 Ghz of cores. On the other guest, there were 10 Ghz of cores and it was peaking at 35% CPU (3.5 Ghz) during peak hours, and even on slower Saturday afternoons it spikes to 15% (1.5 Ghz) every few seconds.
On that 4-core system, it's almost 50% of the total CPU utilization from hardware interrupts. That just shouldn't be happening, even if it is 'normal'. That's a waste of half a VMware host. I hope it's just a driver issue.
I'll post my I/O meter results in the other thread in a moment, but attached here is another screen cap showing the active I/O meter test overlaying the hardware interrupt CPU utilization chart during the 100% read operation.
Matt
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello All.... I am new here.
I am having a issue like this on one of my VM's I am running a Windows 2003 R2 SP2 server running citrix metaframe & all the normal office apps (outlook, word, excel & so on) as the guest OS & the host is a HP DL360 G5 running 2 x quad zeons 1.86Ghz & 10gig of ram. With a 2 x 72gig mirroed & 4 x 126gig 5 raid running off a smart araay P400i. This is runing EXSi 3.
I keep getting my Hardware Interrupts runing at about 13% - 20%.
Any ideas?
Ade
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is somewhat old thread, but has anybody found a cause / fix to this issue yet?
I am having a similar issue on our VMware running on VMware-server 1.0.10 on RHEL5 64bit host. My VM is serving about 100Mb/s on Intel 1Gb ethernet on 2 processors (8 on host), and I am seeing close to 50%-70% cpu utilization for interrupts. I have made sure that no devices are sharing the same IRQ for eth0 device (where all of the interrupts are occurring due to network usage).
I've also investigated a way to throttle down the number of interrupts by setting ethernet driver option such as"options e1000 InterruptThrottleRate=500" in /etc/modprobe.d, but this configuration doesn't seem to take any effect.. maybe because VMware uses virtual device? Has anybody successfully throttle down e1000 interrupts on VMware?
At this point I need a help from VMWare experts on this issue. This issue is totally killing our performance, and I appreciate any help!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Very simmilar problem.
After update to esx 4.1 and installing vmware tools on win 2k3 domain controller, very high CPU usage caused by hardware interrupt.
I think it is manily related to network card, as it happens when users are logging in and out. Than between those times it goes down.
Being a school, it happens quite often.
Any clues anyone?
Edit.
Maybe this will help anyone in the future.
We used standalone converter to clone this machine to another datastore and another vm, and now it works fine.
I'm guessing there was some problem in virtual hardware on old VM. Took few hours to complete, but it works.
Apparently it happened before after update, and VMware will probably include patch for this in next update.
Message was edited by: Cl4v