- VMware Technology Network
- :
- Cloud & SDDC
- :
- VI 3.X
- :
- VI: VMware ESX™ 3.5 Discussions
- :
- T/Sing SAN connectivity issues - VMware, HBA, glas...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
T/Sing SAN connectivity issues - VMware, HBA, glass, fabric, or array?
Twice now in a week I've had this problem. My first instinct is a dying HBA or bad fiber, but a reboot of the ESX host fixes the problem. So, I am wondering if that's where the problem actually lies. Need help troubleshooting to locate source.
Config:
3 - ESX 3.5 u3 hosts w/ 2 Emulex HBA's
2 - Brocade 4100 FC switches
1 - CX4-120
All LUNs are presented to all hosts.
Each host and each SP are connected to both FC switches.
Each HBA -> SP port has a zone created on both switches for any ESX - any LUN
Problem:
- Notification from the SAN of a lost HBA1 on ESX host 1
"Description Initiator (XX:XX...XX:XX) on Server (vmhost1) registered with the storage system is now inactive. It does not have a working physical connection. See alerts for details."
- Checking LUN paths shows all paths on HBA1 dead. Rescan does not fix.
- HBA2 is operating fine, as are both HBA's and all paths on the other hosts....
- Switch error logs show this event in both occurrences. Note: F-port 2 is the HBA in question.
FCPD-1003 - Probing failed on F-port 2 which is possibly a private device which is not supported in this port type
- The FC switch port is showing link errors (see attached)
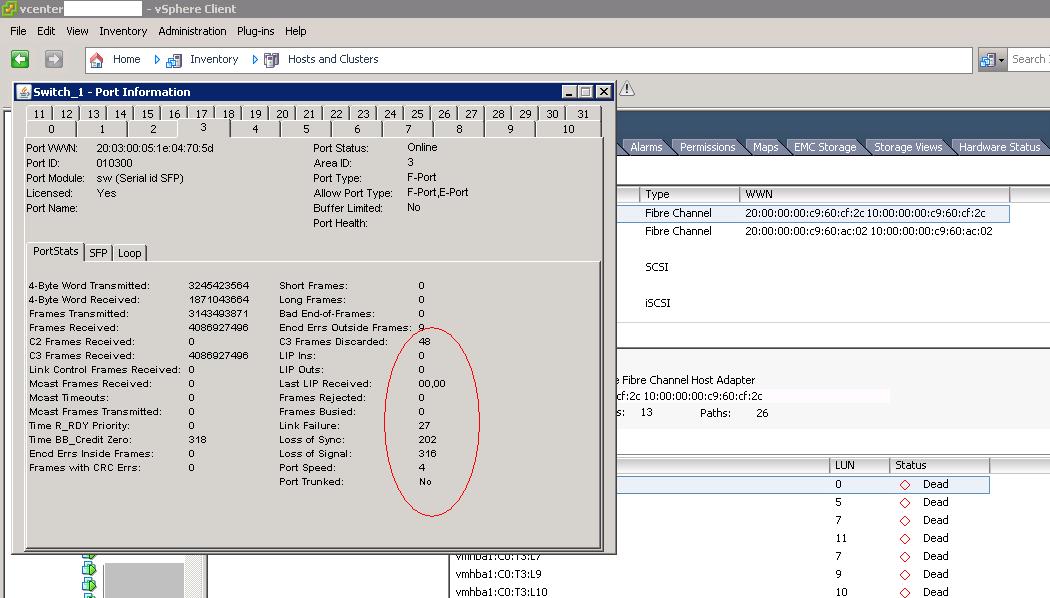{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Update: Changed port on the switch and reset the error count. Watched error count for It failed again this morning.
Interestingly, it seems to be failing on almost exactly 4 day intervals.
SWITCH> 169 Mon Jan 03 2011 09:28:16 UTC Switch 1 4 FCPD-1003 Probing failed on F-port 11 which is possibly a private device which is not supported in this port type
ARRAY> 01/03/11 09:44:04 (GMT) Event Number 720e Server (vmhost1.company.com) registered with the storage system is now inactive.
.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Have you check that HBA firmware is up-to-date?
About the switch zoning are you sure that is correct?
Andre
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I realise this is going to be easier said than done, but I'd suggest upgrading.
Even though those items may be on the HCL for ESX 3.5 - it's an older system, and it may well be plagued with issues not present in newer versions. I know 3.5U4 contained a lot of updates that corrected FC issues for us.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The host is 3.5u4 not u3 as originally posted. My apologies for that. We are upgrading to u5 to be sure. Plan is to go to 4.1, but not until we knock this issue.
The HBA firmware is not up to date, old actually. But it hasn't been up to date for 2 years, and had been running against the same host OS, fiber switch firmware, etc. i.e. no reason for a sudden rash of link failures unless the code just expereinced some "magic" threshold like a poorly handled buffer over run or the like. Upgrading it is on the plan, but not immediately.
As we dig in deeper, it's starting to look like a SFP port facing the array. Why that's causing the HBA's to logout, I'm not sure. One array facing port was very dirty (EncOut), and another had error counts climbing slowly over time. The HBA ports are seeing link failures but zero CRC or Enc errors. This week we will replace two SFP's, upgrade both switches and the host OS. From there we will monitor. The next step will be the HBA and host HW firmware.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I guess I'll put in my 2 cents...
The error on the SAN switch, FCPD-1003, is a Port Login (PLOGI) failure. If it was the HBA or the host, you would most likely be getting Fabric Login (FLOGI) errors along with the PLOGI errors, or seeing some of the error counters on the switch port increment. In your case the PLOGI error on the switch may just be a symptom of the "broken" session between the ESX server and the SAN.
Something to try if you want to keep troubleshooting this passively: zone in a 2nd SAN array, if you have one, and see if this occurs there, too. ![]()
The challenge you have is that you need to replace the SFPs both at the switch and at the SAN. If you replace the SFP(s) on the switch side only, that may not fix it.