- VMware Technology Network
- :
- Cloud & SDDC
- :
- ESXi
- :
- ESXi Discussions
- :
- ESX4 + Nehalem Host + vMMU = Broken TPS !
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Since upgrading our 2 host lab environment from 3.5 to 4.0 we are seeing poor Transparent Page Sharing performance on our new Nehalem based HP ML350 G6 host.
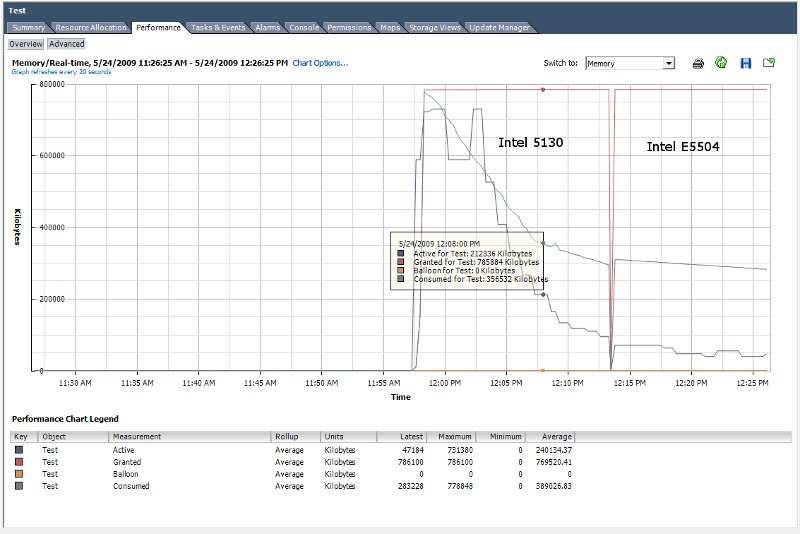
Host A : ML350 G6 - 1 x Intel E5504, 18GB RAM
Host B : Whitebox - 2 x Intel 5130, 8GB RAM
Under ESX 3.5 TPS worked correctly on both hosts, but on ESX 4.0 only the older Intel 5130 based host appears to be able to scavenge inactive memory from the VMs.
To test this out I created a new VM from an existing Win2k3 system disk. (Just to ensure it wasn't an old option in the .vmx file that was causing the issue.) The VM was configured as hardware type 7 and was installed with the latest tools from the 4.0 release.
During the test the VM was idle and reporting only 156MB of the 768MB as in use. The VM was vmotioned between the two hosts and as can be seen from the attached performance graph there is a very big difference in active memory usage.
I've also come across an article by Duncan Epping at yellow-bricks.com that may point the cause as being vMMU...
If vMMU is turned off in the VM settings and the VM restarted then TPS operates as expected on both hosts. (See second image)
So if it comes down to chosing between the two, would you choose TPU over vMMU or vice versa?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As I understand it (feel free to correct me or write a counter-rant if you know it better, this is just my point of view), this issue is rather an unfortunate default setting than a bug, or as someone stated earlier, a tradeoff decision you have to make between TPS and large pages.
Yes, ESX4 has large pages enabled by default with Mem.AllocGuestLargePage being set to 1.
With those large pages, the chance of finding duplicate pages is pretty much zero, hence you won't get any benefits from TPS.
Now you should ask yourself the question, do you really need large pages, does your application actually support it at all (hint: it most likely doesn't)? According to the whitepaper on large page performance, http://www.vmware.com/files/pdf/large_pg_performance.pdf, the benefits of large pages are marginal, and only conceivable if your application actually makes use of them (another hint: pretty much none do).
I don't see why you shouldn't give setting Mem.AllocGuestLargePage to 0 at least a try. The setting is easily configurable for enabling and disabling and doesn't even require a reboot of the host (vmotion VMs off and back though). All it does is disabling the mapping your VMs memory to large pages on the host, and using the good 'ol small pages just like it did by default in ESX3.X.
I have no idea why large pages were enabled by default to begin with, and I guess there won't be a real bugfix (except that fix sets Mem.AllocGuestLargePage to 0 as defautl setting) , since you just can't share duplicate large pages, which don't existent to begin with.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We have set Mem.AllocGuestLargePage to 0 on some test hosts, and it does essentially make the issue 'go away'. While I'd prefer a true resolve, I agree with MKguy that unless we can find hard evidence that this creates a performance issue, it should be set on your affected hosts at least until such time as a fix is released.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Now you should ask yourself the question, do you really need large pages, does your application actually support it at all (hint: it most likely doesn't)? According to the whitepaper on large page performance, the benefits of large pages are marginal, and only conceivable if your application actually makes use of them (another hint: pretty much none do).
Thanks for the link to the doc. So basically it is not enabled in Win2k3 x64 by default anyway (which I verified on my new vm SQL server), and it's not even clear that SQL supports it or has it enabled by default. So I don't see how it could hurt me to set Mem.AllocGuestLargePage to 0, because in essence the guest OS isn't making use of the feature anyway.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

{kind=link}
{kind=link}
Yes thank you MKguy... I did give it a try, I made the change 2 days ago.
My problem as stated earlier is the alerting or monitoring of my VM's and SNMP going nuts (or did I not make that clear)
They still show alerts in the status WHILE the guest memmory is now showing OK since the change.
So please tell me again that "this issue is rather an unfortunate default setting than a bug".
Either way, my boss does not care, I am on the hook for it, and if fixing it means I have to go back to 3.5.
Bottom line is; in the interest of keeping my job.....I get to work this weekend for free!
yay
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Help me understand something. Rajesh said you can ignore if your memory is not over committed. So if my memory is over committed I can do the Mem.AllocGuestLargePage fix and as long as I don't need large pages it will be OK?
Even if that is the case I am also experiencing the same thing dephcon5 is.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Forgive me guys, but my father always taught me growing up not to try to fix the symptoms but to solve the problem...
We're essentially talking about band-aids here, not a "fix".
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I agree with that and it was my bad for calling it a fix. As you say it is a band aid. However if all I have is a band aid maybe I can stop the bleeding until a real fix is forthcoming. VMware?
Lucky for me my boss is OK with turning the alerts off vs. reinstalling 3.5. And it does seem like the Mem.AllocGuestLargePage to 0 normalizes the memory useage reporting with the excpetion of the alerts. At first I thought it did not but I just was not being patient enough.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok, on a long shot I restarted the VPXA service and the MGMT service and the vCenter alerts stopped AND the VM's are behaving much like they did when on 3.5.
To summarize:
I have SEVEN DL380 G6 HP servers with two X5560 Intel Nehalem quad core's and 72GB of ram in each host. My vCenter server is a slightly older G5 HP server with SQL 05 ent (for what ever that is worth).
My ESX 4 servers are new and were not upgraded from 3.5, however all the VM's are migrated from my old 3.5 ESX host and tools was updated at the time of migration.
I did the "set Mem.AllocGuestLargePage to 0" and then migrate all the VM's off then back. (I waited 2 hours and no change)
I restarted the vCenter server services (no change) I then rebooted my vCenter server. (no change)
On a long shot I decided to restart the vxpa and mgmt services on each ESX host and now my VM's are no longer showing in an alarm state.
Im not sure if I would call this fixed but.... the peformance of my VM's seems to be as good as I had expected from the upgrade in hardware, the alarm state seems to be correct now in that I am not flooded with SNMP and vCenter looks normal.
Everything else seems to be working ok and when I intentionally flodded a test print server with traffic, it did generate an alarm which at least tells me I am at a good baseline to go forward.
For me, the ticket was the restarting of the vxpa and mgmt services AFTER the "set Mem.AllocGuestLargePage to 0".
Your mileage may vary...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Will I still be able to use this prescribed workaround if I don't have the ability to use vMotion (using direct-attached storage on only 1 host)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
"For me, the ticket was the restarting of the vxpa and mgmt services AFTER the "set Mem.AllocGuestLargePage to 0"."
I take it this was done from ssh. Forgive my ignorance but can that be done with guest running on the host or do they need to be vmotioned first?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You will have to shut down the guest and restart the host but it should work fine.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, ssh session to your ESX boxen. Log in as root or escalate to root with su -
then run service vmware-vpxa restart
and service mgmt-vmware restart
I did NOT restart any hosts or VM's to execute these commands.
I think you could restart the ESX boxes and acomplish the same thing, but I did not try that so I can not verify that.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Following up on my previous posting. We are currently testing the fix.
Could not put the fix in the next patch but if testing goes out OK, fix will be in the patch after that.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dephcon5, Thanks that works great. Even though this is a workaround it does make me feel better that the VMs are acting normally. I am a little disapointed that VMware does not have the complete steps documented.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Several people have, understandably, asked about when this
issue will be fixed. We are on track to resolving the problem
in Patch 2, which is expected in mid to late September.
In the meantime, disabling large page usage as a temporary
work-around is probably the best approach, but I would like
to reiterate that this causes a measurable loss of performance.
So once the patch becomes available, it is a good idea to go
back and reenable large pages.
Also a small clarification. Someone asked if the temporary
work-around would be "free" (i.e., have no performance penalty)
for Win2k3 x64 which doesn't enable large pages by default.
While this may seem plausible, it is however not the case.
When running a virtual machine, there are two levels of memory
mapping in use: from guest linear to guest physical address and
from guest physical to machine address. Large pages provide
benefits at each of these levels. A guest that doesn't enable
large pages in the first level mapping, will still get performance
improvements from large pages if they can be used for the second
level mapping. (And, unsurprisingly, large pages provide the
biggest benefits when both mappings are done with large pages.)
You can read more about this in the "Memory and MMU Virtualization"
section of this document:
http://www.vmware.com/resources/techresources/10036
Thanks,
Ole
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for you reply, Ole. The one thing that's been bothering me the most is the lack of input from VMware.
I appreciate you chiming in...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I wanted to throw one thing out there for server 2008 64-bit people. We found that if we allocated 4GB of RAM to a virtual Server 2008 64-bit server (may apply to 32-bit also) the OS would cache data into the physical memory, based upon what the OS "thought" you would use. We found this service from Microsoft to control the memory usage, and were able to put a cap on it. Here is the link:
After setting this service up on all our server 2008 64-bit VM's and enabling the Mem.AllocGuestLargePage to 0 we are now noticing almost a 50% decrease in the amount of physical ram used on the ESX servers. Before enabling the Microsoft Windows Dynamic Cache Service and Mem.AllocGuestLargePage we were using about 110GB of RAM on our ESX cluster. After putting the fixes in and rebooting ESX hosts and VM's, memory usage is down below 50GB. Performance has stayed about the same in the VM's.
Hopefully this helps some other people.
Ben
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Does this mean only Nehalem Host have this problem as thread mentioned it "Re: ESX4 + Nehalem Host + vMMU = Broken TPS !"
So AMD is not involved by this bug?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have observed this problem in my environment on an AMD-based server (see my previous post).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is there anymore news re a date for a fix for this?