- VMware Technology Network
- :
- Cloud & SDDC
- :
- ESXi
- :
- ESXi Discussions
- :
- Re: ESX4 + Nehalem Host + vMMU = Broken TPS !
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
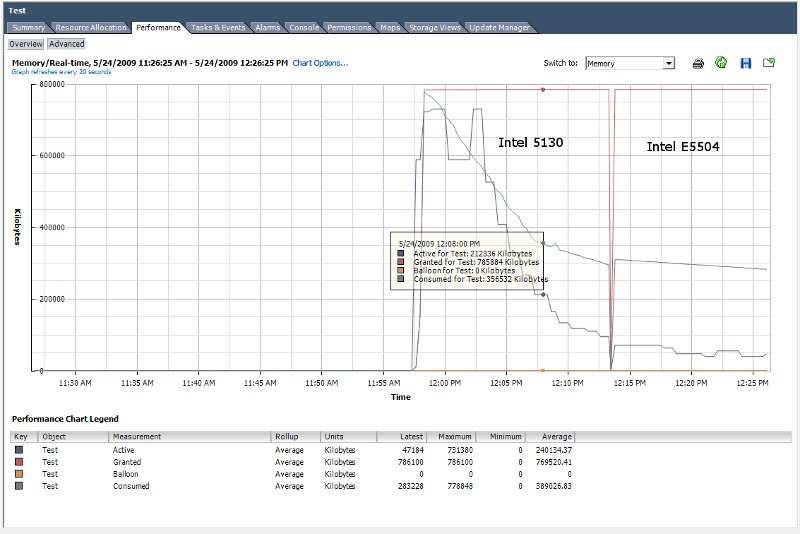
Since upgrading our 2 host lab environment from 3.5 to 4.0 we are seeing poor Transparent Page Sharing performance on our new Nehalem based HP ML350 G6 host.
Host A : ML350 G6 - 1 x Intel E5504, 18GB RAM
Host B : Whitebox - 2 x Intel 5130, 8GB RAM
Under ESX 3.5 TPS worked correctly on both hosts, but on ESX 4.0 only the older Intel 5130 based host appears to be able to scavenge inactive memory from the VMs.
To test this out I created a new VM from an existing Win2k3 system disk. (Just to ensure it wasn't an old option in the .vmx file that was causing the issue.) The VM was configured as hardware type 7 and was installed with the latest tools from the 4.0 release.
During the test the VM was idle and reporting only 156MB of the 768MB as in use. The VM was vmotioned between the two hosts and as can be seen from the attached performance graph there is a very big difference in active memory usage.
I've also come across an article by Duncan Epping at yellow-bricks.com that may point the cause as being vMMU...
If vMMU is turned off in the VM settings and the VM restarted then TPS operates as expected on both hosts. (See second image)
So if it comes down to chosing between the two, would you choose TPU over vMMU or vice versa?
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
VMware, now would be a good time to at least give us a rough estimation of a date for a fix. The actual situation is intolerable.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Honestly, this is ridiculous. I am seriously considering moving our virtualized environment over to HyperV or a different solution because of the non-existent response from VMWare on this issue. The whole situation indicates to me that VMWare does not care about supporting it's product. Not to mention that I have run into countless other serious bugs since version 4 of ESX + vCenter.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good morning. I understand your concerns, and I'll
try to find out more specific information today. At
this point, the only information I have is the rough
date estimate that I posted on August 6.
Sincerely,
Ole
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Not to mention that the vCenter client is not supported at all on Windows 7, and the workaround doesn't work on RTM. VMWare seems to be rapidly going down hill at a very inopportune time for them (considering all the increased competition in the virtualization space now).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have the information from my system vendor (VMwarepartner), that Vmware will release this month (september) a patch where solved the problem.
Regards Toby
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Not to mention that the vCenter client is not supported at all on Windows 7, and the workaround doesn't work on RTM.
The workaround works for me. I am running vCenter client on Win7 RTM.
Edit: Oops, upon re-reading I see you mentioned a vCenter client. I double-checked and I am running the VMware vSphere Client under Win7 RTM. Sorry about the mixup.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The problem will be fixed in Patch 02, which we
currently expect to be available approximately
September 30.
Thanks,
Ole
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I had experienced the same issues in our hosting environment after standing up an 8-host cluster using HP DL380 G6 systems with Intel X5560 Nehalem processors. Long story short, I set the Mem.AllocGuestLargePage to 0, put each host into Maintenance Mode to force a vMotion of the running VM's, then back out of Maintenance Mode. Bingo, no more issues or alarms... Seems straight forward and the trade off in terms of performance has gone un-noticed to this point. We run a slew of systems ranging from Win2003 to Win2008 (32 and 64 bit) with SQL, Exchange, Oracle, etc. No impact to customer facing applications or query jobs. As a definite plus, I saw utilization on the hosts go from an average of 45% down to 20% for memory consumption and VM guest memory utilization went from 95%+ in some cases down to 2%. I understand the benefits of hardware MMU and fully look to utilize it where it makes sense, but as a whole the 4k page size does seem to handle the TPS function at a level that most clients should expect considering it's one of the main selling points of VMware ESX over any of the other virtualization suites out there.
My big question is this - if you set the Mem.AllocGuestLargePage on a host to 0, is there a way to granularly enable the 2M large page size for a VM independently? This would allow me to enable large memory pages for my heavier hitting VM's without setting it up across the board.
Thanks in advance.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ryan,
My big question is this - if you set the Mem.AllocGuestLargePage on a host to 0, is there a way to granularly enable the 2M large page size for a VM independently? This would allow me to enable large memory pages for my heavier hitting VM's without setting it up across the board.
Unfortunately, no. Once you disable large pages at the host level, you cannot turn on large pages at per-VM level.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Got it. Thanks for the quick reply... I understand that the 2M page size effectively breaks down to 4k page sizes on memory overcommit at the host level, but I won't see that benefit for a little while on the hosts that I have running. We're set up for 30 host clusters with an average of 30-40 VM's across 72GB RAM configs. The hosts peak occasionally, but the overcommit isn't a standard practice for us. I'll wait for the patch to drop and test in our labs for the final verdict before I go back to large pages as a default. For now all seems quiet and I can breathe easy knowing we haven't shot our VM:host ratio in the foot by going to ESX 4.0 :smileygrin:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There are two issues discussed in this thread.
1) High guest memory usage while using large pages
This issue will be fixed in patch02.
2) Low (or zero) TPS numbers while using large pages
Please check my Feb 21, 2006 post. Low TPS numbers while host memory is under-committed is totally fine because TPS will automatically kick-in if/when host memory gets over-committed. However, we made few TPS improvements that will help to share zeroed pages in some special scenarios even while host memory is under-committed. For example, Windows OS zeros all guest memory at power-on and the improved TPS will share the guest pages that are zeroed by guest OS bootup code. Once the guest starts actually using the zeroed memory, ESX will back the guest memory with large pages to reduce TLB misses and improve performance. This TPS improvement will most likely ship in the first update.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Does the "zeroed out" behavior also take place on Linux boot up as well? A quick Google search didn't yield any results.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Linux does not zero memory eagerly during boot.
Sincerely,
Ole
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As a quick question, if EPT is large page based, is it possible to align the guest operating system large/huge pages to the VMM pages? Seems like there would be benefit in doing that similar to aligning to 64k blocks for the VMDKs when attached to NAS/SAN.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, we preferentially use large pages to back guest
memory where the guest is also using large pages. In
other words: it's done ![]()
Thanks,
Ole
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have to admit I'm confused how they hypervisor would know the alignment of the memory pages in the guest operating system. For example, when I lock huge pages in Linux, I have to make a kernel parameter change in sysctl.conf defining how many huge pages (2 MB pages) I should use. How does vSphere know which pages I have set to huge pages, since not all of the guest can be set to huge pages?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, it is difficult for hypervisor to know which guest pages are being used as large pages inside the guest. vSphere uses various techniques to deduce this info and the techniques used depends on whether software or hardware MMU (i.e., RVI or EPT) is used.
When vSphere is using software MMU
- Hypervisor reads guest page tables to setup shadow page tables. So it can infer whether guest is mapping a memory region large or small.
When vSphere is using hardware MMU
- Hypervisor normally does not need to read guest page tables. If host memory is undercommitted and there are bunch of free host large pages, vSphere backs guest memory with host large pages even though guest is not mapping the memory region large. In some benchmarks, mapping all guest memory with host large pages shows much improved performace even when guest is not using large pages. As discussed in this thread, backing all guest memory large has some side-effects with respect to "guest memory usage" estimation and TPS. These will be fixed soon.
- Sometimes it may not be possible to map all guest memory with large pages (e.g., memory overcommit situations). So vSphere selectively reads guest page tables and uses sophisticated heuristics to determine which guest memory regions need to be mapped large.
Note that large page backing of guest memory may not be possible because host memory is fragmented. To avoid this, vSphere implements efficient memory defragmentation algorithms.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Why is there still not a kb article on this issue? At least I could not find one searching active memory usage, or Nehalem processors. Why the secrecy over what is affecting a large number of your install base? Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jeg er ikke på kontoret fra d. 17/9/2009 til mandag d. 28/9/2009.
Ved uopsættelige henvendelser kan service desk kontaktes på 89498599
I'm out of office from 17/9/2009 until Monday 28/9/2009
Urgent matters can be directed to our service desk on +45 89498599