- VMware Technology Network
- :
- Cloud & SDDC
- :
- ESXi
- :
- ESXi Discussions
- :
- Re: ESX4 + Nehalem Host + vMMU = Broken TPS !
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Since upgrading our 2 host lab environment from 3.5 to 4.0 we are seeing poor Transparent Page Sharing performance on our new Nehalem based HP ML350 G6 host.
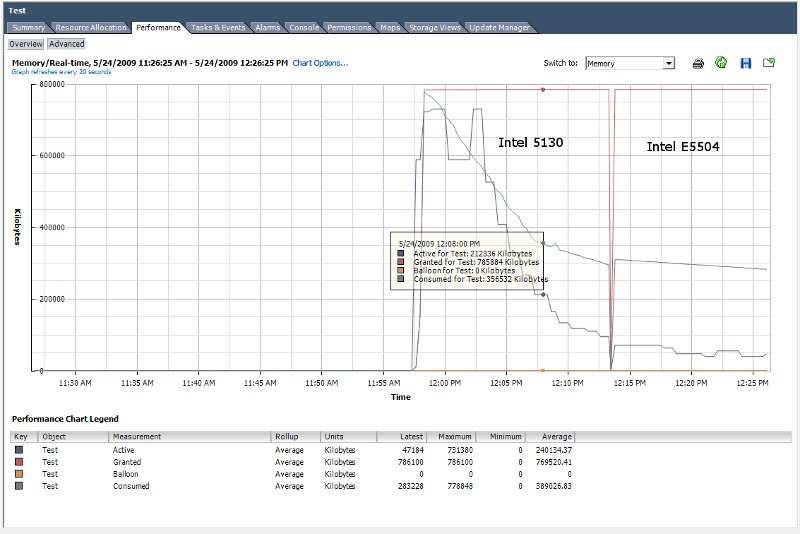
Host A : ML350 G6 - 1 x Intel E5504, 18GB RAM
Host B : Whitebox - 2 x Intel 5130, 8GB RAM
Under ESX 3.5 TPS worked correctly on both hosts, but on ESX 4.0 only the older Intel 5130 based host appears to be able to scavenge inactive memory from the VMs.
To test this out I created a new VM from an existing Win2k3 system disk. (Just to ensure it wasn't an old option in the .vmx file that was causing the issue.) The VM was configured as hardware type 7 and was installed with the latest tools from the 4.0 release.
During the test the VM was idle and reporting only 156MB of the 768MB as in use. The VM was vmotioned between the two hosts and as can be seen from the attached performance graph there is a very big difference in active memory usage.
I've also come across an article by Duncan Epping at yellow-bricks.com that may point the cause as being vMMU...
If vMMU is turned off in the VM settings and the VM restarted then TPS operates as expected on both hosts. (See second image)
So if it comes down to chosing between the two, would you choose TPU over vMMU or vice versa?
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Great to hear! Any inside-info on around when we can expect to see this first update?
Thank you!!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I really don´t want to be barefaced - i REALLY don´t! But this issue IS serious and had have to be fixed in the GA. Now you are telling us it will be fixed in the first update. When will this first update be? I am still waiting till this is fixed till i turn these DELL 710´s into production! Please give us a date! This is more than important.
best,
Joerg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hoi,
I had the same problems on 2 rx 300 s5 with nehalem xeon x5550 cpu`s. All 64bit systems equal linux or windows 2008 had guestmemory 90 %. I solved it and now, it is all pretty good. First I set the Mem.AllocGuestLargePage to 0, then i shutdown my win 2008 vm.
After that I set the cpu/mmu-virtualization from auto to software in the option menu from the 64bit vm.
I started vm-machine and wait 5 min, all seems good. Next day I shutdown the vm again and set cpu/mmu-virtualization to auto.
After start and waiting 5 min, all seems good the guestmemory went down to 2%.
Now I shutdown again -> set the modus from auto to Intel VT (EPT) and started the vm. (I mean in auto modus, the esx took the Hardwarevirtualization)
Guestmemory oki, vm memory parameters ok.
This I had done with 4 Windows 2008 64bit and by all vm`s it was the same result .
Now it`s all good.
ESX-Version: ESX 4.0.0, 175625
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Setting Mem.AllocGuestLargePage to 0 may reduce performance for some workloads. Check . Please set the Mem.AllocGuestLargePage config option to 0 after careful analysis of your VM's workload.
If your ESX server's memory is undercommitted, then Nehalem and AMD Barcelona/Shanghai machines may show high "Guest Memory Usage". But, it does not have any bad side-effect, so you can choose to ignore high guest memory usage.
When an ESX server's memory is overcommitted, you are unlikely to see high "Guest memory usage" and ESX server will reclaim memory from unimportant idle VMs so that it can satisfy the memory demand of active and important VMs.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Rajesh, there have been several reports of this issue on other types of processors.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Charadeur,
Even in other processors, you can choose to ignore the high "Guest memory usage" if your ESX server's (and cluster's) memory is undercommitted because it should not have any effect on performance of VMs.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Add another customer to the list. We have Dell R710s that are experiencing the issue too. VMware, please fix this soon!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Same issue on DELL M710, M610.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Me too, 2x R610 . Vmware, when we can expect a fix?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Unfortunatly I am over committed on memory and this is a real problem for us.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey Guys -
I am also experiencing the same problem on HP BL490's with Nahalem processors. I built 5 new Server 2008 64-bit VM's with 4GB of RAM each. All are acting as domain controllers, each VM shows 3.6 - 3.9 GB of Guest RAM usage. When looking at task manager within the VM, actual RAM usage is a little over 1GB. Any update on when this will be fixed?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
edited t remove out of office message.
Message was edited by: joergriether
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Bonjour,
Je serai absent du bureau jusqu'au 21/08 inclus.
Vous pouvez pour toutes vos demandes habituelles vous adresser à Nicolas VASSILIADIS au +33892895312 ou bien par email : nvassiliadis@blueacacia.com
Bonne journée,
Alexandre NEY
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I've read through this thread and I'm surprised to find this has been a known issue as long as it has. I am seeing the same issues with my Nahalem based Dell R710's but I'm not sure I have enough understanding to make an educated decision as to whether I should set Mem.AllocGuestLargePage to 0 or not, because quite frankly, a lot of the discussion is over my head ![]() How will I know that there are any issues with the guest VM, or if it's just a false positive? I am inclined to leave things how they are until there is an update, but we are about to push a large production SQL DB that is currently a physical machine into vSphere4. It is W2K3 Enterprise x64 and SQL x64 with 16GB of memory. It is bothersome to see it reporting 98% guest memory when there is not a single user logged in!
How will I know that there are any issues with the guest VM, or if it's just a false positive? I am inclined to leave things how they are until there is an update, but we are about to push a large production SQL DB that is currently a physical machine into vSphere4. It is W2K3 Enterprise x64 and SQL x64 with 16GB of memory. It is bothersome to see it reporting 98% guest memory when there is not a single user logged in!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Time to break out the old-school Windows methods of monitoring your server performance!
Task Manager, Perfmon, etc...
And yes, we're all (impatiently) waiting for this to be fixed...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm seeing this same issue. We have Primergy RX300 S5 server with Intel Xeon E5540 CPUs.
I hope, the problem will fixed soon.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My advice is I would not roll out my critical SQL server if I was over committed on the ESX memory.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Oh I wish I found this thread before migrating 1/2 my VM's to new hosts.
SNMP is going nuts on me and I am in a real tight spot.
I am not permitted to disable the alerts and I can not decipher between a VM thats crying wolf and a VM that is in real trouble.
My boss is blaming me for not knowing about this before migrating 1/2 of my guest machines to the new Nehalem powered 380 G6 HP servers.
So do I migrate the VM's back? I will have to remove tools and reinstall the previous version, and do it all AGAIN when this supposed fix comes out.
I can see it now, my new host servers will sit doing nothing (except consume power) till November. What a collossal waste of time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I wish I had something more positive to share - but multiple different support techs have all implied that we're not looking until around November at the earliest. I'd love to believe threads like this would expedite things, but let's look at it from their perspective...
A) Release an update prematurely before full testing cycles and risk what they define as an 'annoyance' to grow in to an actual functionality 'problem'
B) Wait the full testing cycle and do it "right".
I can understand that side of things, but that really doesn't help those of us who find ourselves in a difficult place because of this. My boss would likely have my head (my job?) if he knew that right now on our brand new ESX4 servers - there is no alerting enabled because of this problem. I'm very anxious about getting alerts turned on and fully functioning but just can't because of this.
You likely need to migrate those VMs back if disabling the alerts is not an option. Yes - you're sharing in the nightmare many of us others are...
My boss is wanting me to look in to a potential VMware ACE/View deployment (replacing our entire desktop infrastructure with VMware), but I'm extremely reluctant because of all of this... 😕 I'm such a huge VMware fanboy, but this is truly doing some damage to my confidence...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That's where VMware is making the mistake....classifying this as an 'annoyance'. Not being able to monitor your Virtual infrastructure is more than an annoyance, it's a serious problem for several customers.
With how aggressive competition has become in the virtualization market VMware can't afford to not listen to their customers demands...especially with their brand new flagship product -- it's really tarnishing an otherwise great release.
Wake up VMware and listen to your customers -- we want an out-of-cycle hotfix for this issue now!