- VMware Technology Network
- :
- Cloud & SDDC
- :
- VMware Aria
- :
- VMware Aria Operations Discussions
- :
- Re: Alerting on non-OS filesystem usage on Linux
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Alerting on non-OS filesystem usage on Linux
Hi Guys,
We have the EPOps agent deployed to a number of Red Hat 6 VMs, and have noticed that we are not seeing Alerts for non-OS file systems when they hit Warning, Immediate or Critical thresholds.
OS file systems (e.g /, /opt, /var, /home etc) all alert correctly, whereas custom file systems (e.g /applogs, /appdata) do not.
When drilling down through the OS object within vROps, I can see that the metrics are being gathered for each "FileServer Mount" (see screenshot), but these metrics are not being alerted on.
How do we configure vROps to alert on ALL linux filesystems (as it seems to do for Windows) current and future? Or is it a case of changing the Metric / Property Symptom definition each time a VM comes along with a new file system? This seems like unnecessary administration
Thanks,
Dan

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
NFS mounts are shown under RPC and not under FileServer Mount. Can you check if it is listed under RPC
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
These are not NFS mounts....we have opened a call with VMware, hopefully they have a solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am from vROps R&D team. i am looking to check this inhouse.
It will be helpful if you can brief how you had created these custom filesystems and what you have mounted on them(Eg from your post - /appdata and /applogs).
Can you also paste the output after running fstab command on the linux machine, for us to know what kind of a mount it is
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Output from fstab below.
/dev/mapper/rootvg-rootvg / ext4 defaults 1 1
/dev/mapper/rootvg-perfloglv /perflog ext4 defaults 1 2
/dev/mapper/rootvg-tmplv /tmp ext4 defaults,nodev,nosuid,noexec 1 2
/dev/mapper/rootvg-usrlv /usr ext4 defaults 1 2
/dev/mapper/rootvg-varlv /var ext4 defaults 1 2
/dev/mapper/rootvg-optlv /opt ext4 defaults 1 2
/dev/mapper/rootvg-swaplv swap swap defaults 0 0
/dev/mapper/datavg-wasappdatalv /wasappdata ext4 defaults 0 0
/dev/mapper/datavg-optmqmlv /opt/mqm ext4 defaults 0 0
/dev/mapper/datavg-varmqmlv /var/mqm ext4 defaults 0 0
From a filesystem type perspective we have a combination of ext4 on RH6 and jfs on RH7.
(NB We have WAS and MQ installed)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
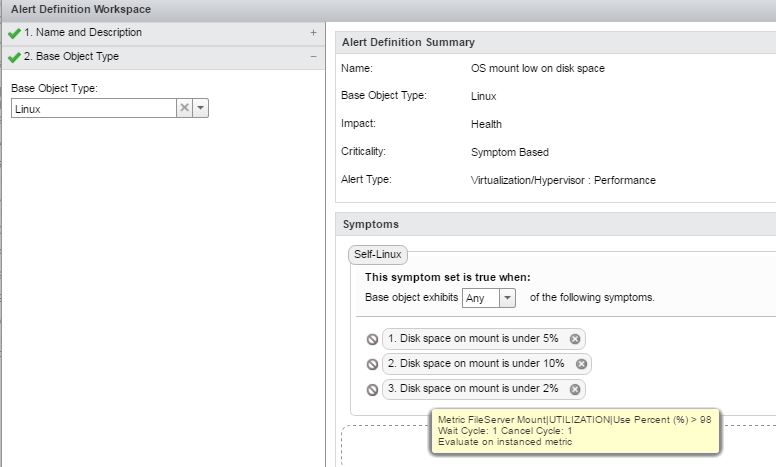
As a further note, the metric "FileServer Mount | Use Percent (%) " from the EP Ops adapter has no defined/built-in alerts in vROps.
However, the same metric from the Hyperic adapter DID have these alerts - and they were defined at the top level to capture ANY disk mounts current and future. (See below screenshot)
If we attempt to create a new alert definition for the equivalent EP Ops metric, we are only able to choose a specific disk mount and therefore would have to create one for each mount we have. Hopefully this makes sense!?!
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So to update this, I've managed to find a "workaround"
I created new symptom definitions, and chose the base object type of EP Ops Adapter -> Linux.
When choosing the metric to use, I selected FileServer Mount, and then a random mount point/utilization/use percent (%) metric as shown in Dan's previous screenshot.
Once I had selected this for the new symptom, I configured the name and static threshold level, but under the Advanced option I selected the "Evaluate on instanced metric" check box. The bubble tip had eluded to the fact that if I was to do this, it would use all instances of this metric. (I.E the metric for each of the available fileserver mounts)
By doing this, and then adding this symptom to a new alert we now received disk alerts for all mounts. Technically we could add the new symptoms to the existing alert, but we wanted to differentiate between the two. (At least initially)
It's not great, but it works. If you look at the symptom it still shows as being based on the specific instance of the metric I chose at random, but it does appear to work for all mounts across all VGs.