- VMware Technology Network
- :
- Cloud & SDDC
- :
- VMware vSphere
- :
- VMware vSphere™ Discussions
- :
- Re: ESXI 6.7 Missing Datastore
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
ESXI 6.7 Missing Datastore
Hi,
My ESXI box has been working fine but tonight I gave it a reboot and upon coming back up one of my datastores has vanished ![]() , the drive the datastore is on shows as present in the devices. I have included pictures, please can someone help me?
, the drive the datastore is on shows as present in the devices. I have included pictures, please can someone help me?
It has been restarted before without issue so not sure why it did this on this reboot.
thank you for your help
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorry I should confirm it is the WD 6TB data store that has dropped off.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You should check vmkernel.log but first please check hardware status in iLO/iDRAC
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
2019-01-11T18:24:18.828Z cpu0:2100627)VSCSI: 2623: handle 8193(vscsi0:0):Reset request on FSS handle 1903127 (0 outstanding commands) from (vmm0:Win10)
2019-01-11T18:24:18.828Z cpu1:2097331)VSCSI: 2903: handle 8193(vscsi0:0):Reset [Retries: 0/0] from (vmm0:Win10)
2019-01-11T18:24:18.828Z cpu1:2097331)vmw_ahci[0000001f]: scsiTaskMgmtCommand:VMK Task: VIRT_RESET initiator=0x4306c91130c0
2019-01-11T18:24:18.828Z cpu1:2097331)vmw_ahci[0000001f]: ahciAbortIO:(curr) HWQD: 0 BusyL: 0
2019-01-11T18:24:18.830Z cpu1:2097331)VSCSI: 2691: handle 8193(vscsi0:0):Completing reset (0 outstanding commands)
2019-01-11T18:24:23.815Z cpu2:2100630)VSCSI: 2623: handle 8193(vscsi0:0):Reset request on FSS handle 1903127 (0 outstanding commands) from (vmm0:Win10)
2019-01-11T18:24:23.816Z cpu0:2097331)VSCSI: 2903: handle 8193(vscsi0:0):Reset [Retries: 0/0] from (vmm0:Win10)
2019-01-11T18:24:23.816Z cpu0:2097331)vmw_ahci[0000001f]: scsiTaskMgmtCommand:VMK Task: VIRT_RESET initiator=0x4306c91130c0
2019-01-11T18:24:23.816Z cpu0:2097331)vmw_ahci[0000001f]: ahciAbortIO:(curr) HWQD: 0 BusyL: 0
2019-01-11T18:24:23.818Z cpu0:2097331)VSCSI: 2691: handle 8193(vscsi0:0):Completing reset (0 outstanding commands)
2019-01-11T18:24:27.191Z cpu3:2099503 opID=31585358)World: 11942: VC opID 9f7e87d6 maps to vmkernel opID 31585358
2019-01-11T18:24:27.191Z cpu3:2099503 opID=31585358)NVDManagement: 1478: No nvdimms found on the system
2019-01-11T18:24:58.159Z cpu2:2099503 opID=95984d55)World: 11942: VC opID 9f7e87ef maps to vmkernel opID 95984d55
2019-01-11T18:24:58.159Z cpu2:2099503 opID=95984d55)NVDManagement: 1478: No nvdimms found on the system
2019-01-11T18:25:19.119Z cpu1:2099504 opID=c1c18dae)World: 11942: VC opID 9f7e8813 maps to vmkernel opID c1c18dae
2019-01-11T18:25:19.119Z cpu1:2099504 opID=c1c18dae)NVDManagement: 1478: No nvdimms found on the system
2019-01-11T18:25:26.659Z cpu3:2099504 opID=4b9f1017)World: 11942: VC opID 9f7e881c maps to vmkernel opID 4b9f1017
2019-01-11T18:25:26.659Z cpu3:2099504 opID=4b9f1017)VC: 4616: Device rescan time 477 msec (total number of devices 9)
2019-01-11T18:25:26.659Z cpu3:2099504 opID=4b9f1017)VC: 4619: Filesystem probe time 54 msec (devices probed 6 of 9)
2019-01-11T18:25:26.659Z cpu3:2099504 opID=4b9f1017)VC: 4621: Refresh open volume time 2 msec
2019-01-11T18:25:33.746Z cpu1:2100631)vmw_ahci[0000001f]: CompletionBottomHalf:Error port=1, PxIS=0x40000008, PxTDF=0x4041,PxSERR=0x00000000, PxCI=0x00000000, PxSACT=0x00000002, ActiveTags=0x00000002
2019-01-11T18:25:33.746Z cpu1:2100631)vmw_ahci[0000001f]: CompletionBottomHalf:SCSI cmd 0x28 on slot 1 lba=0x2105, lbc=0x100
2019-01-11T18:25:33.746Z cpu1:2100631)vmw_ahci[0000001f]: CompletionBottomHalf:cfis->command= 0x60
2019-01-11T18:25:33.746Z cpu1:2100631)vmw_ahci[0000001f]: LogExceptionSignal:Port 1, Signal: --|--|--|--|--|TF|--|--|--|--|--|-- (0x0020) Curr: --|--|--|--|--|--|--|--|--|--|--|-- (0x0000)
2019-01-11T18:25:33.746Z cpu1:2097568)vmw_ahci[0000001f]: LogExceptionProcess:Port 1, Process: --|--|--|--|--|TF|--|--|--|--|--|-- (0x0020) Curr: --|--|--|--|--|TF|--|--|--|--|--|-- (0x0020)
2019-01-11T18:25:33.746Z cpu1:2097568)vmw_ahci[0000001f]: ExceptionHandlerWorld:Performing device reset due to Task File Error.
2019-01-11T18:25:33.746Z cpu1:2097568)vmw_ahci[0000001f]: ExceptionHandlerWorld:hardware stop on slot 0x1, activeTags 0x00000002
2019-01-11T18:25:33.758Z cpu1:2097568)vmw_ahci[0000001f]: _IssueComReset:Issuing comreset...
2019-01-11T18:25:33.761Z cpu1:2097568)vmw_ahci[0000001f]: ExceptionHandlerWorld:fail a command on slot 1
2019-01-11T18:25:33.761Z cpu2:2097177)NMP: nmp_ThrottleLogForDevice:3689: Cmd 0x28 (0x459a40ddf600, 2098561) to dev "t10.ATA_____WDC_WD60EFRX2D68MYMN1_________________________WD2DWXP1H644T6R8" on path "vmhba0:C0:T1:L0" Failed: H:0x0 D:0x2 P:0x0 Valid se$
2019-01-11T18:25:33.761Z cpu2:2097177)ScsiDeviceIO: 3029: Cmd(0x459a40ddf600) 0x28, CmdSN 0x11 from world 2098561 to dev "t10.ATA_____WDC_WD60EFRX2D68MYMN1_________________________WD2DWXP1H644T6R8" failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x4
2019-01-11T18:25:33.761Z cpu2:2097177)0x44 0x0.
2019-01-11T18:25:40.214Z cpu1:2100630)vmw_ahci[0000001f]: CompletionBottomHalf:Error port=1, PxIS=0x40000008, PxTDF=0x4041,PxSERR=0x00000000, PxCI=0x00000000, PxSACT=0x00000002, ActiveTags=0x00000002
2019-01-11T18:25:40.214Z cpu1:2100630)vmw_ahci[0000001f]: CompletionBottomHalf:SCSI cmd 0x28 on slot 1 lba=0x2105, lbc=0x100
2019-01-11T18:25:40.214Z cpu1:2100630)vmw_ahci[0000001f]: CompletionBottomHalf:cfis->command= 0x60
2019-01-11T18:25:40.214Z cpu1:2100630)vmw_ahci[0000001f]: LogExceptionSignal:Port 1, Signal: --|--|--|--|--|TF|--|--|--|--|--|-- (0x0020) Curr: --|--|--|--|--|--|--|--|--|--|--|-- (0x0000)
2019-01-11T18:25:40.214Z cpu1:2097568)vmw_ahci[0000001f]: LogExceptionProcess:Port 1, Process: --|--|--|--|--|TF|--|--|--|--|--|-- (0x0020) Curr: --|--|--|--|--|TF|--|--|--|--|--|-- (0x0020)
2019-01-11T18:25:40.214Z cpu1:2097568)vmw_ahci[0000001f]: ExceptionHandlerWorld:Performing device reset due to Task File Error.
2019-01-11T18:25:40.215Z cpu1:2097568)vmw_ahci[0000001f]: ExceptionHandlerWorld:hardware stop on slot 0x1, activeTags 0x00000002
2019-01-11T18:25:40.237Z cpu1:2097568)vmw_ahci[0000001f]: _IssueComReset:Issuing comreset...
2019-01-11T18:25:40.240Z cpu1:2097568)vmw_ahci[0000001f]: ExceptionHandlerWorld:fail a command on slot 1
2019-01-11T18:25:40.240Z cpu2:2097177)ScsiDeviceIO: 3029: Cmd(0x459a40cbfcc0) 0x28, CmdSN 0x11 from world 2098561 to dev "t10.ATA_____WDC_WD60EFRX2D68MYMN1_________________________WD2DWXP1H644T6R8" failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x4
2019-01-11T18:25:40.240Z cpu2:2097177)0x44 0x0.
2019-01-11T18:26:05.651Z cpu2:2097605)NMP: nmp_ResetDeviceLogThrottling:3519: last error status from device t10.ATA_____WDC_WD60EFRX2D68MYMN1_________________________WD2DWXP1H644T6R8 repeated 1 times
2019-01-11T18:28:58.869Z cpu0:2099507 opID=e7f908d4)World: 11942: VC opID 9f7e8846 maps to vmkernel opID e7f908d4
2019-01-11T18:28:58.869Z cpu0:2099507 opID=e7f908d4)NVDManagement: 1478: No nvdimms found on the system
2019-01-11T18:29:49.727Z cpu1:2098567 opID=a78e4732)World: 11942: VC opID 9f7e885b maps to vmkernel opID a78e4732
2019-01-11T18:29:49.727Z cpu1:2098567 opID=a78e4732)NVDManagement: 1478: No nvdimms found on the system
2019-01-11T18:30:03.406Z cpu1:2098888 opID=d0558922)World: 11942: VC opID 9f7e8873 maps to vmkernel opID d0558922
2019-01-11T18:30:03.406Z cpu1:2098888 opID=d0558922)NVDManagement: 1478: No nvdimms found on the system
2019-01-11T18:30:12.500Z cpu1:2099505 opID=c59ce772)World: 11942: VC opID 9f7e8885 maps to vmkernel opID c59ce772
2019-01-11T18:30:12.500Z cpu1:2099505 opID=c59ce772)NVDManagement: 1478: No nvdimms found on the system
2019-01-11T18:30:23.398Z cpu1:2098888 opID=189c4607)World: 11942: VC opID 9f7e8896 maps to vmkernel opID 189c4607
2019-01-11T18:30:23.398Z cpu1:2098888 opID=189c4607)NVDManagement: 1478: No nvdimms found on the system
2019-01-11T18:31:40.895Z cpu0:2099502 opID=39d36182)World: 11942: VC opID 9f7e890f maps to vmkernel opID 39d36182
2019-01-11T18:31:40.895Z cpu0:2099502 opID=39d36182)NVDManagement: 1478: No nvdimms found on the system
2019-01-11T18:39:22.699Z cpu1:2098574 opID=f4a77e5)World: 11942: VC opID 9f7e897e maps to vmkernel opID f4a77e5
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I have attached the log above and see errors relating to the drive but I am not sure what it means or how to fix.
it looks like it reset the connection in the reboot?
Thank you
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Log gives this sense code for that WD device -- >H:0x0 D:0x2 P:0x0 Valid sense data: 0x4 0x44 0x0.
Additional sense code 0x4 0x44 0x0. (0x44 indicates INTERNAL TARGET FAILURE) most likely a hardware issue. Check if you see any hardware errors related to the disk in your hardware monitoring tool.
Suresh
https://vconnectit.wordpress.com/
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It detected the VMFS, try to rescan again and see if the Datastore is getting mounted automatically. Ideally, it should not wipe out the data if we mount , but fingers crossed.
Use voma command from ESXi ssh session and check for errors
Checking Metadata Consistency with VOMA
Suresh
https://vconnectit.wordpress.com/
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
A rescan did not add automatically ![]()
Should I run the voma command in SSH before trying the new data store option?
Thank you
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
first run 'esxcli storage vmfs extent list' to check mappings from device to uuid
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have had similar issues with vSphere 6.5, however it was with a FC array. Rescan and Refresh would usually resolve the issue after a few minutes.
Let us know if you find a fix.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
Thank you for everyone’s input so far ![]()
I took the drive out and connected to another machine and ran a file scan on the drive, all the vmdk and flat files are on there as they were before in the Datastore.
I am thinking it may be best to copy these off to other drives before I go any further in case anything further wipes them and I have no backup. I will need to do this Monday though when I have access to some large drives ![]() .
.
Once I do have the files backed up what would be the next stage?
Do I try and remount this drive manually or do I create a new Datastore using the wizard hoping that it will not delete the files?
thanks again ![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would say try an re-mount the drive again. However if it does not work, I would do a format and recreate the datastore. Obviously you should make sure that those VMs you are copying off works before you do the format.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Nmh I am not sure if your issue is resolved or not, but if its still present then please share the Host hardware details such as make and model, because there is a known bug with HP systems.
Along with as you see the device has the VMFS partitions available and data is there, try mounting the DS manually using the commands listed.
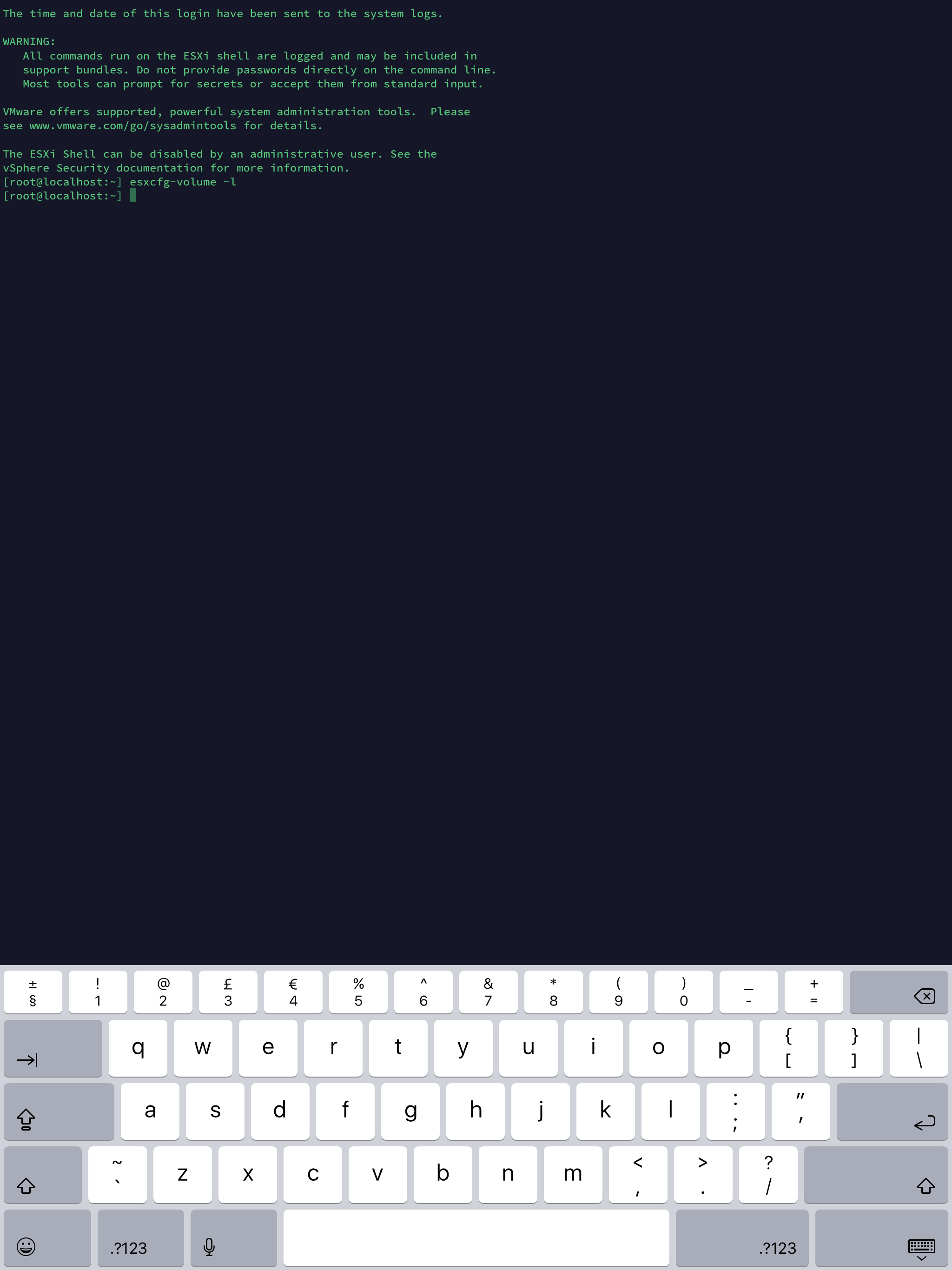
"esxcfg-volume -l" this will list all the volumes.
Below are the list of options you can use from esxcfg-volume
esxcfg-volume
esxcfg-volume <options>
-l|--list List all volumes which have been
detected as snapshots/replicas.
-m|--mount <VMFS UUID|label> Mount a snapshot/replica volume, if
its original copy is not online.
-u|--umount <VMFS UUID|label> Umount a snapshot/replica volume.
-r|--resignature <VMFS UUID|label> Resignature a snapshot/replica volume.
-M|--persistent-mount <VMFS UUID|label> Mount a snapshot/replica volume
persistently, if its original copy is
not online.
-U|--upgrade <VMFS UUID|label> Upgrade a VMFS3 volume to VMFS5.
-h|--help Show this message.
Use the command esxcfg-volume -m UUID of the device listed in previous command.
I Hope this helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Unfortunatley this is still an issue ![]() , I am putting trouble shooting on hold until tomorrow when I can move off and test data so I know it’s safe.
, I am putting trouble shooting on hold until tomorrow when I can move off and test data so I know it’s safe.
The drive is a WD with an intel motherboard and processor.
Which tool do I run these commands in, will SSH via putty be Ok?
thank you
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, you can use putty to launch ssh session. Post the output of all commands here if possible.
Suresh
https://vconnectit.wordpress.com/
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, please connect SSH session and perform these commands.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
> I took the drive out and connected to another machine and ran a file scan on the drive, all the vmdk and flat files are on there as they were before in the Datastore.
Please explain what you did exactly. If possible use that other host to copy out your VMs.
________________________________________________
Do you need support with a VMFS recovery problem ? - send a message via skype "sanbarrow"
I do not support Workstation 16 at this time ...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The log messages shows some failure on the vmw_ahci controller. Not sure why it would behave after a reboot. But you can check how many AHCI controllers are there. Try a rescan and see if it works. If not
1. Then run below commands
esxcli system module list | grep vmw_ahci
If the Native AHCI driver shows disabled then run below command to enable it
esxcli system module set --enabled=true --module=vmw_ahci
2. If the above does not help check vibs using
esxcli software vib list | grep ahci
If this shows both sata–ahci and vmw_ahci vib , then try disabling vmw_ahci driver and let it use the sata-ahci driver.
Via SSH: esxcli system module set –enabled=false –module=vmw_ahci
After entering this command, reboot your host