- VMware Technology Network
- :
- Cloud & SDDC
- :
- vSphere vNetwork
- :
- vSphere™ vNetwork Discussions
- :
- Re: Heavy network usage leads to strange drops obs...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Heavy network usage leads to strange drops observed in the network/realtime performance graph.
I've got a Windows 2008 R2 guest running on a white box Intel Server motherboard (two integrated Intel gigabit network cards, plus two offboard Broadcom 5709 based nics) using ESX 4.1 Essentials. The 2008 R2 guest is using the Microsoft software iSCSI initiator to connect to volumes hosted on a separate, physical Openfiler server. When I format a disk that is connected via iSCSI it generates a significant network load, roughly 350mbits/second constantly according to the Resource Monitor in 2008 R2. My issue is when I'm observing the realtime network performance graphs. There is a drop every few minutes and the transmit rate of the vmnic (that is the uplink to the rest of the network) is displayed as N/A. I have observed the same network behavior on separate segments/adapters used for the software iscsi initiator built into ESX 4.x when connected to three different types of targets (openfiler, HP MSA, Cybernetics miSAN). I'm convinced it is a network adapter driver or vswitch issue for the uplink port. I get the same network drops when migrating VM guests between hosts, too, so it shouldn't be related to iSCSI. I'm attaching a screen capture for reference. Any insight into this issue will be greatly appreciated.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Most likely Openfiler is flushing it buffers during those drops, I see same behavior with my very low-end NFS storage.
Tomi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Perhaps try to isolate this a bit... we have both storage and networking as possibilities here. Can you use iperf to generate network load to verify that it's specific to networking?
iperf: http://www.noc.ucf.edu/Tools/Iperf/ (you want the v1.7.0 Windows binary.)
Server side: iperf -s -w 2m
Client side: iperf -w 2m -t 60 -c
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It's definitely network related and not storage related. I ran iperf (via jperf) between a physical Windows 7 computer and a guest Server 2003 vm and the network drops manifested the same as before.
The only change I have made, without any positive effect, is to disable flow control on the vm's host servers. The Windows 7 workstation already has flow control off by default.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
OK, let's go with your hunch about a network driver first.
Since you have two types of network cards in your machine, can you perhaps try to move your VM from one type of card to another and see if the problem moves with the VM or stays with the card?
Next, you can put two VMs on into separate port groups (on the same or different adapters) and have them send traffic to each other. Any traffic traversing two separate port groups (regardless of whether they're on the same vSwitch) will get sent over the wire - at least, that was the way it was in 3.x.
If that still produces the problem, see if putting two VMs onto the same port group and having them talk to each other eliminates the problem - if it doesn't, we're probably dealing with something inside the guest OS, as we'd not be going through the physical adapter (or its driver) at all.
Finally, if you can run "esxcfg-nics -l" on the console (whether ESX or ESXi) we should be able to see which network driver is being used. A glance through /var/log/vmkernel (ESX) or "grep vmkernel /var/log/messages|less" (for ESXi) might also yield useful bits of information.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I ran iperf between two vms on the same host, on the same vswitch, and the speeds were registering about 700mbps with no speed drops noticed. Between one of the same vms and a physical computer there would be speed drops down to 300/500mbps for a second, presumably because the uplink pnic on the vswitch is dropping connection and/or re-negotiating it's speed and settings. When I was testing our miSAN with a direct connection between it and the ESX host via a single, straight through cable, I had Cybernetics look at our logs and they noticed that the network card on the miSAN was dropping to 10mb speed every few minutes, coinciding with the N/A graph drops, which I'm sure was a response to the ESX host dropping connection at those times.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Quick addendum, I've got our miSAN hosting a LUN to a Windows 7 computer using the software iscsi initiator built in and it has not dropped connection during load when the LUN was being full formatted to NTFS. I had Cybernetics review the logs just after and there were no drops in connection or speed. This Windows 7 computer was using the same hardware as a test ESXi 4.1 install that I've been using for this testing. It's not a hardware issue. It has to be a software issue in ESX(i) 4.1.
All the host servers I've tested have used the inbox drivers that come with 4.1:
bnx2 version 2.0.7d with firmware 5.2.2
e1000 version 8.0.3.2-1vmw-NAPI
e1000e version 0.4.1.7.1-1vmw-NAPI with firmware 1.3-0
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Did you get the same results with both types of network adapters? There are known issues with the bnx2x (10GigE) driver, but I've not had any issues with either bnx2 or e1000, both of which we (and thousands more) use extensively.
Also, can you please check that the adapters are set to Autonegotiate? vSphere is sometimes a bit silly and sets them to 1000/Full, which is technically not allowed. I think they mostly have it in there for cosmetic reasons, but it's definitely a good idea to set it on Autonegotiate.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I've tried all three different physical nic types as the uplink for the vswitch(s) and they all exhibit the same symptoms.
Autonegotiate is on. I've tried with manual settings with no success, too.
I've also used unmanaged, web managed and full managed gigabit switches from d-link, 3com, and cisco respectively and none of them made a difference, either.
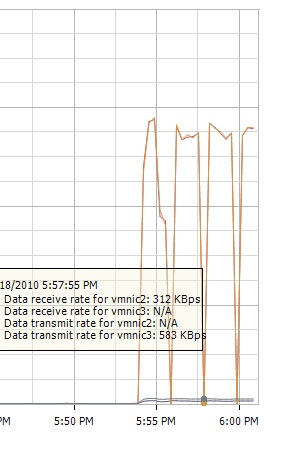
Also, there are never any alarms, as if the cable was disconnected, so the nic is not completely losing connection. On all of the graphs, the transmit speed is the only one to fall to N/A, the receive speed seems unaffected.
For the heck of it, I'm going to move one VM to a separate vswitch on the same broadcast domain and set up an iperf session between it and another VM on the same host and broadcast domain and see what happens.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here's the result of running iperf between to VMs on the same host where each VM is on a separate vswitch connected to the same physical switch so that they stay on the same broadcast domain.The transmit rate of one uplink falls to N/A at the same time as the receive rate of the other uplink falls to N/A.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Cool, those are some interesting results. I think we have pretty much ruled out network drivers as a possibility here: the chances of both e1000 and bnx2 having the exact same flaw that - apparently - only occurs on your particular machine are pretty remote.
It's time we dive a little deeper into the logs and setup. For this you'll need to get onto the console of the machine, I suspect remote administration with SSH will be your best bet. You'll need to start "Remote Tech Support" in the security profile configuration screen first, then SSH into the box using something like PuTTY. (Note: I think the default settings shuts it down again after a few minutes, which is a good thing.)
Once in the remote administration shell, run the following commands and post the results:
esxcfg-nics -l
esxcfg-scsidevs -a
esxcfg-vswitch -l
esxcfg-mpath -L (note: uppercase "L")
For ESXi: the last 20 or so lines of "grep vmkwarning /var/log/messages"
For ESX: the last 20 or so lines of /var/log/vmkwarning
Also scan through the text of "grep vmkernel /var/log/messages | less" (for ESXi, or just /var/log/vmkernel for ESX) for any messages that appear around the time that you encounter the problem. I don't think it's necessary to post 1000 lines from two weeks ago, mostly just stuff that's pertinent now. This may not necessarily be network-related, but could help identify a root cause.
Finally, if you've not done so yet - and I know this might sound silly but you've not mentioned it yet - please replace the cables and give it another go. I appreciate that the problem did not occur with Windows 7 on it, but it would make the voices stop ![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Oh, and one more thing before we dive that deep, can you please confirm the following:
whether VMware Tools is installed and up to date inside the VM
on the options tab of the VM's properties, what Guest OS is selected
what network adapter type is visible inside the VM (e.g. e1000, vmxnet, vmxnet2, vmxnet3, etc.)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
All the guests are running the latest VMware tools. The network cards in the guests are e1000. The guests are running either 64bit Windows Server 2003 R2 or 64bit Windows Server 2008 R2 (gotta love TechNet). This is on my home / test network. I've tried different cables at different times and it doesn't seem to influence things.
All the other requested info is attached.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Forgot to mention. There is no vmkernel for iSCSI or iSCSI targets configured on any of my home host servers, right now. I can produce the symptoms without them.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the feedback, reason I asked for the storage bits as well is that sometimes issues around the underlying storage can have a weird impact in high-load situations. At first glance, that doesn't appear to be the case here.
I'm not exactly sure when the problem occurred, but there are some potentially "interesting" "memory" events around the time the NIC is connected. From other posts these memory events are possibly processor-related, rather than memory.
Some questions:
Was the NIC physically disconnected at the times the logs indicate?
If available, at what time were you conducting the test?
You're confident that you tested on the NC382T (Broadcom) as well? I ask because I've had cases in the past where I just changed the adapter order in the vSwitch properties, and the VM would not move to the new "preferred" NIC unless I unlinked the NIC from the vSwitch or disconnected/reconnected the VM.
Having looked at the output of "esxcfg-nics -l", I can see that the current Intel NIC that is connected is the Intel 1000 GT Desktop adapter. Doing some searching about the silicon on that NIC (Intel 82541GI), I can find quite a few Linux-related problems with it. Though ESX is not Linux-based, a lot of the hardware drivers share elements with Linux counterparts. (That particular NIC is also not on the ESX HCL.)
The other Intel NIC is also a bit weird - the MAC address only varies in the last nibble, which usually indicates a dual-port NIC, yet I can see they're on completely seperate busses and use different silicon. Odd. Regardless, it's also a lower-end desktop NIC and also does not appear to be on the HCL.
Next steps:
Please can you re-test with the HP NC382T? Use esxtop networking screen ("n") to confirm that the VM is actually bound to either vmnic1 or vmnic2
What is the memory situation on the machine? Please open esxtop, switch to the memory screen ("m"), copy & paste what's displayed
Finally, please try adding a vmxnet3 adapter to the VM and test using that again
(I realise this is a lot of "testing" - appreciate the time you're putting into this! Hope we can get this solved, otherwise support is going to ask you to start over ![]() )
)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
Just curious: have you been able to make any progress towards a solution?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Has anyone foud a solutions for this problem.
We are experiencing the same issue withe the dropdowns in the Vm graphs.

{kind=link}
{kind=link}
We have not found anything that explains this behaviour.
We are running Citrix servers on thos hosts and the end users complain about hickups in their sessions. So when they type something it lags behind for a couple of seconds and then goes on.
We are using a SUN 600 blade chassis with 10 Gb Nem modules.
We ar now testing on a Hp DL380 G7 with a 10Gb adapter and are seeing simular behaviour.
When we are connecting only 1 Gb modules we don't see the problem.
Any help will be greatly appreciated.