- VMware Technology Network
- :
- Cloud & SDDC
- :
- VI 3.X
- :
- VI: VMware ESX™ 3.5 Discussions
- :
- Re: Loss of switch causing VI to shutdown?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This morning my boss was moving some power cables around to different PDU's one of them being a Gig switch hosting 1/2 of our ESX NICs. For (what we thought) was redundancy reasons we split the ESX host NICs onto two different Gig switches incase one went down the other would keep going. I wasn't in the office for this but I got an early phone call to come in when the infrastructure went down. Looking at the vpx logs once he pulled the power on that switch (which also contained the NIC connection for our physical VC) virtual machines started powering down. Among our virtual machines were our domain controllers which also house our DNS so that might be another issue to consider.
I have a ticket open with VMware already but I was curious if anyone might point out something wrong in our configuration as to why when the switch went down all the VM's started to power off.
Kyle
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
All the settings I referred to are part of the Advanced options within HA. If you extend out your isolation response time, I don't necessarily see any downfalls to it, especially if your Host isolation response is set to "Leave VM Powered ON"
Here's a great link on what can be configured.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
See that is what you get when you let your boss touch stuff ?:| - were you running HA and was your isolation response configured to power down VMs? Because it sounds like the isolation response kicked in and when DNS went down it hose HA from bringing them back up - just my assessment -
If you find this or any other answer useful please consider awarding points by marking the answer correct or helpful
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Do you have HA/DRS configured? I am not sure but this looks like more of a split brain situation in which the physical switch failure may cause all the primary servers in a HA setup to not being able to reach other and start powering of the VMs for fail over to other hosts , but that never happend as other host is not reachable , and VC disconnection may have made it worse.
Thanks,
Samir
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Doesn't isolation mean that it can't talk to anything or any other host? We do have some configured to shutdown in that case but machines that weren't configured were shut down as well. Also in the ESX host files we have manually put in the other hosts in case we lost our DNS so they would be able to talk to all the other servers including our VC. I'm not sure if we put that manual entery into our VC though

Kyle
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Loss of vc should not cause this type of problem, but loss of DNS may very well have. Once you configure HA from vc, the servers basically keep track of each other, but if DNS is gone, and they can't talk to each other anymore, then as weinstein5 stated, you may have ended up with all of your hosts thinking they were isolated, which would cause them to perform their isolation response. Depending on your version, by default this would be to poweroff the vm's.
-KjB
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you had hosts entries, then DNS should not have caused this issue. Make sure your host entries are correct. Also make sure the VLAN you are using to talk on the network for your service console is available on both of your physical switches.
-KjB
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
it is not to the other host - HA looks towards the SC gateway - if it can not see the gateway it will assume it is isolated and will initiate the isolation response -
If you find this or any other answer useful please consider awarding points by marking the answer correct or helpful
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Well once I got in, I was able to login to the hosts, power on our DC/DNS server from the host VIC and then was able to reconnect all the hosts from our VC (right click -> connect) which brought everything back online, almost like they all powered back up. Very weird. VLAN is pretty easy to diag since its only one VLAN... I know I know about the whole splitting of the networks, security etc... I've brought it up numours times but they don't want to do it or spend the money on the changes. ANYWAYS... I checked the hosts files again on the ESX boxes and apparently I only manually entered in the other ESX hosts, not the VirtualCenter server. Also there are no manual entries in the hosts file on the VirtualCenter server.
Per my suggestion we're going to be adding DNS functionality to our physical backup server which should prevent DNS issues if we have a failure like this in the future.
Kyle
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I believe that he also pulled the power from our ASA firewall device as well.... which would be our SC gateway
Even if that did trigger HA and some of the rules said to power off, why would the other VM's power off? They're set to "use cluster settings" where can I check to see what those default cluster settings might be?
Kyle
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Those would be set in the main cluster settings -
If you find this or any other answer useful please consider awarding points by marking the answer correct or helpful
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Which would be right here - Power Off VM

So at any point the ESX host can't contact the SC Gateway is it going to trigger an isolation response? Or was this compounded because it lost the main switch, couldn't talk to the rest of the network including the SC gateway?
Kyle
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
there is a 15 second default heartbeat time. If within that time the host(s) doesn't respond an isolation event will be triggered. You can do a couple things to help in keeping you VM's on-line during an HA isolation event. You can increase the heartbeat time, create a second COS, or use your VMotion NIC as the heartbeat.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Troy 's answer is right on target -
If you find this or any other answer useful please consider awarding points by marking the answer correct or helpful
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If the HA agents cannot contact eachother, and are unable to contact the SC gateway, they will trigger the isolation response.
So in your case, both hosts decided they were the one being disconnected, and both triggered their isolation response.
Apparently your SC connection isn't as redundant as you thought it was.
If you had 2 physical nics backing the vswitch your SC port group was on, each connected to a different switch, this would not have happened.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
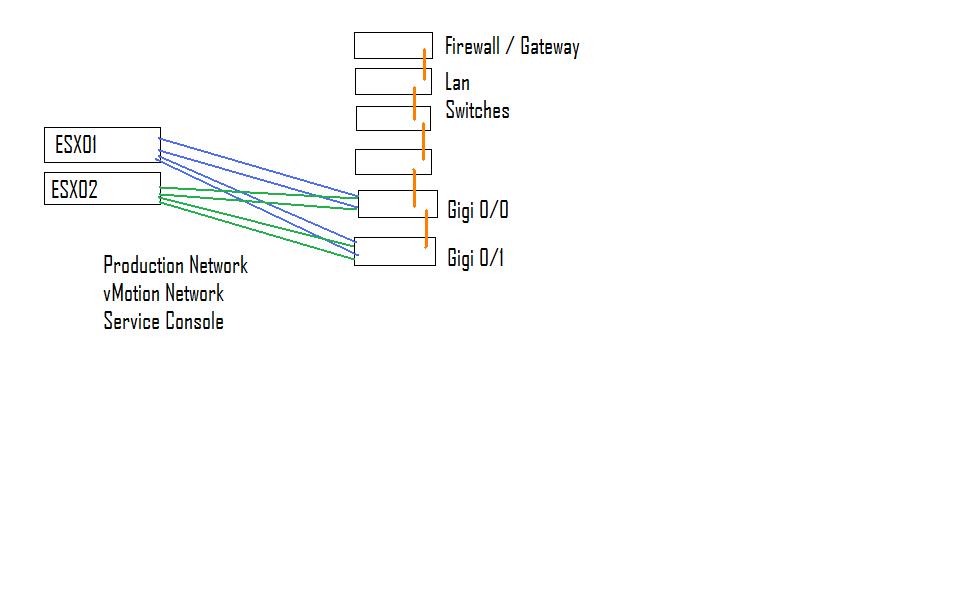
Sorry for this really crappy drawing using mspaint but here is kinda a legist of what it looks like...
Power was pulled from Gigi 0/0 so there were still two paths for production network / vMotion / SC to the other gigi switch 0/1, but there was no path for it to go anywhere else. Obviously HA is a good thing to have enabled, as long as it is configured correctly. Troy for changing the HA heartbeat timers and or what is used for it, where would that be done, how practical is it to do and are there any concerns I should have doing it? Obviously if I changed it to the vmotion NICs I would never have an isolation event unless both switches went down or I lost all 4 NICs, but then again that would be for sure an isolation event... What problems would possibly come up from extending the heartbeat timers?
Kyle
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
could you post a screenshot of your network configuration from the vi client?
and of the teaming policies for the physical nics /portgroup
if the service consoles were still connected to each other by the Gigi 0/1 switch, HA should not have kicked in, even if the gateway was unreachable.
so either there is something amiss in your configuration, or your boss actually took both switches out (let's not forget about the boss ![]() )
)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
All the settings I referred to are part of the Advanced options within HA. If you extend out your isolation response time, I don't necessarily see any downfalls to it, especially if your Host isolation response is set to "Leave VM Powered ON"
Here's a great link on what can be configured.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think the main issue we're having is our switch configuration is wrong for our setup. When we origionaly migrated and had help with all the p2v and upgrading our hardware/infrastructure we thought we had redundant switches, but it looks like the way they're tied together along with the rest of our LAN switch configuration is a single point of failure. The networking on the ESX side (minus it being not secured) is solid and the way it's setup works, and would've worked if our switch configuration was truely redundant. As for the boss aspect, I'm about 99% sure he didn't pull out the second switch seeing as his boss was there as well.
Troy - thanks for the advanced HA configure page from Duncan. I'll have to read through that and see what I can take from it. Appriciate you guys giving your opinion on what might have happened, much faster than what VMware has done but then again they're looking through endless logs from all our hosts and VC ![]() It's given me a better picture of what actually happened and made sense from some log files I was going through where things didn't add up in my head (ha-eventmgr event ***** PS01 is powering off).
It's given me a better picture of what actually happened and made sense from some log files I was going through where things didn't add up in my head (ha-eventmgr event ***** PS01 is powering off).
I guess the most vaulable lesson that probably could've come out of this is if you're going to start pulling plugs from ESX / VC, disable HA....
Kyle
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I guess the most valuable lesson that probably could've come out of this is if you're going to start pulling plugs from ESX / VC, disable HA....
Ain't that the truth!!