- VMware Technology Network
- :
- Cloud & SDDC
- :
- VI 3.X
- :
- VI: VMware ESX™ 3.5 Discussions
- :
- Re: Apparent problem with Adaptec 5805
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Apparent problem with Adaptec 5805
We are trying out the eval version of ESX3.5. We have observed several occurrences of ESX getting confused while copying large numbers of files between VMs that have their virtual disks on a RAID managed by an Adaptec 5805. Here are the particulars:
ESX server 3.5.0, kernel 2.4.21-47.0.1.ELvmnix
Supermicro X7DWA system board, dual Xeon E5450 3.00GHz
boot banner BIOS info: Serial ATA AHCI BIOS, iSrc 1.12_E.smci0 12102007
var/log/messages BIOS info: Pheonix version 6.00 released 12/21/2007
Adaptec unified serial RAID card 5805, BIOS v5.2-0[15728]
var/log/vmkernel: Adaptec aacraid_esx30 driver (1.1-5[d-8930]custom-IBM)
The Adaptec card is on the ESX hardware list, and we appear to have the correct driver, unless the custom-IBM tag in the log means something different.
What happens is that at some apparently random point during the XCOPY, all VMs on the host will hang. They will not respond to pings nor to the console in the VI client. The host itself will answer a ping, but VI client cannot connect to it. Examining the log files via the host console, it appears that ESX is in an infinite loop, logging, VSCSIFS: 235: Failed reset of virtual target, over and over again (with some other messages too). The host stays in the loop until we reboot it.
If we try the same test with VMs that have their virtual disks on drives just connected to the SATA controller on the system board, everything is fine.
Has anyone else had trouble with this card, or seen this type of behavior with any hardware?
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hiya,
I read very recently on the RHEL5 or CentOS mailing that there was a driver performance issue with the AACRAID driver, that would cause some scsi reset on high I/O transactions, but for all normal 'I/O' requests, the card behaves normally. I'm trying to search for such info in Red Hat bugzilla's site now.
In any case, I just checked on Adaptec's website, and they have a more recent driver for AACRAID. Linux AACRAID Driver 1.1.5-2453 . According to the Linux v1.1.5-2453 Readme PDF , there is a device driver that is enabled for
aacraid-driverdisk-i686-VMware.img: RH Floppy Driver Disk
2.4.21-47.0.1.EL 2.4.21-47.0.1.ELvmnix
Maybe you might have a go at replacing the AACRAID driver with the more recent one. Unfortunately this is not an operation that I have tried, and it might not solve you're solution. It's just an idea...
Erik
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Erik,
Thank you for the information. I downloaded the new drivers from Adaptec, extracted the one that appears to apply to my system, put it on a floppy disk by using dd, mounted the floppy, and executed the update.sh script on it. It said it was skipping the three boot options, but appeared at the end to have installed. However, after restarting the system and checking the vmkernel log, it is still the old driver (2415) that gets loaded.
I have never used a Linux driver disk before. Is there something obvious I am doing wrong?
Anyway, thanks again for the help. I had hoped to report that your input fixed the problem.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I've experienced a very similar problem with an Adaptec 5805.
During moderate pre-prpoduction stress testing of one of our Windows 2003 NFS servers (running 9 VMs, performing an online backup of those VMs at 90 MB/s to tape, and importing another VM with VMware Converter, over 3 seperate network interfaces), the RAID 10 array hosted by the 5805 stopped responding and generated this error:
The description for Event ID ( 129 ) in Source ( arcsas ) cannot be found. The local computer may not have the necessary registry information or message DLL files to display messages from a remote computer. You may be able to use the /AUXSOURCE= flag to retrieve this description; see Help and Support for details. The following information is part of the event: \Device\RaidPort0.
That is a pretty unuseful error message, but essentially what happened is that the server was still operating but lost contact with the raid array. A pretty serious short coming for a brand new raid controller! The firmware and windows drivers are current and the controller has a fan situated above it and is running at 55c under load so heat shouldn't be an issue.
I'll be following this up with adaptec support, if they can't resolve the issue I'll be forced to drop all adaptec cards. I can't say I wasn't warned, I saw a number of complaints about the reliability of other adaptec controllers on various forums, but its still disappointing.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
enm_lti,
Were you able to solve this issue, I have an esx 3.5 server, here, tried two seperate Adaptec 5805 cards with fw build 15738, and the I/O on these services is totally unstable, I get purple screens of death at full load, or if just restarting the server & unmounting the filesystems.
I cant get the latest adaptec driver to install either.
James.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
James,
We abandoned the Adaptec controller. We wanted to switch to ESXi anyway, so in the process we switched to an LSI MegaRAID card, and everything has been working very well.
-Eric
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thanks for that, is the performance good?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't have any real benchmarks, and I don't know what kind of performance you are accustomed to. For 2 weeks we've been running on this platform a machine that serves HTTP and FTP and does some data processing as well, and we have not been able to detect any performance difference as compared to when this computer ran on a physical machine. The traffic is light, but there is traffic, it's not just sitting there. This is the only VM on it so far, but we are planning to add others soon.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I've got one of these, and I've been having similar issues, however my array would eject one of the drives as it failed, forcing it into rebuild mode. Then if it crashes again whilst rebuilding it creates bad stripes (effectively bad blocks in the volume) that can't be fixes without nuking the array and starting over.
It also runs stupidly hot if i dont have the case covers on.
Theres a new BIOS and Driver as of 1st August 2008, so I've installed the BIOS and am re-building with 3.5 Update2 now... wheee. Luckily I managed to pry the VM files out of the array onto a SATA drive.
The Adaptec site lists a new driver for ESX, but I'm not sure if this is accurate, I was under the impression that drivers from ESX came from VMware only...?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Oh guys, before I forget - I managed to solve this issue, whilst increasing the I/O performance at least 20 or 30%.
Turns out there is no driver issue with the 5805, its just this card doesnt seem to like sharing IRQ's with COS drivers, particularly the USB drivers loaded on ESX startup.
All you have to do it disable USB on the mainboard, or find an IRQ work around. The problem may be different for different boards, depending on slot layout & IRQ assignment. In my case it wasnt just affecting performance, but esx would crash.
Disabling USB @ bios level makes everything run awesome, no drivers load, the hardware gets assigned dedicated IRQ's, runs great, 5805 is a fast card. See these sites for more information:
good luck, james.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Im having similar problems.
I have narrowed this problem down to the Adaptec 5805 card I have.
I have a RAID10 with 4 Seagate cheetahs as well as a RAID1 with 2x 300GB cheetahs. Finally I have a 750gb Seagate utility disk.
We have a single SBS 2003 VM and when I first took it out it was crashing twice a night (usually during backups)
I moved the VM over to the seagate utility disk and I did not have a problem with it crashing at all for about a week, put it on the mirrored drive same thing, no problem.
Decided to put it back to the RAID10 array and twice today it has crashed to a PSOD.
This morning I disabled the USB controllers in the BIOS and moved the 5805 to the outboard slot. It just crashed again, while I was trying to turn a VM on which means another 45min round trip to switch it back on again.....
I am going in in the morning to update the firmware on the 5805 to the latest version as well as reinstall ESX with the latest version.
Do you think it would be worth recreating the RAID10 array as well?
Also is it worth installing the ACRAID driver listed on the Adaptec site for ESX? I have never installed a driver manually through ESX or Linux and am not entirely sure how to do it or if its even worth doing as I thought ESX would have the better suited driver anyway.
Will see if it makes things any more stable, if this does not work, I will put it back to the Seagate drive and let it run like that until I can order another RAID card.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just to update this problem.
I upgraded the Adaptec 5805 firmware from a version in march to the August version.
Its a long winded process which requires 7 floppy disks, so anyone that has to do this might want to grab a cheap USB FDD.
Also moved our VM from the raid 10 array to the Mirrored array.
Updated the Intel motherboard bios (pretty sure it was latest anyway)
Disabled the USB from the Console as described in one of the articles above (modprobe -r usb-uhci)
Fingers crossed..... If it runs ok for the next week I will say problem solved, just in case I am going to order another raid controller as it cannot hurt to have one in stock anyway.
Next step will be to change the RAID controller.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I've got my 5805 working perfectly now.
I'm running the latest firmware from 1st August 2008 (flash it using a DOS USB key... not 7 floppies :-P)
I've disabled USB on my board to sort any possible performance issues (not that I had any) and checked for IRQ conflicts with the COS.
I've changed my Western Digital WD6400AAKS and Samsung HD642JJ SATA drives for WD10EACS drives that are on Adaptec's supported list -
No more array pauses, no more data corruption, no more drive ejects. I've been punishing it all week and its been perfect.
YAY!
The only down side is that the supported drives are 2/3rds the speed of the drives I had bought originally....
Now for VMware/Adaptec to get IPMI hardware monitoring working.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Nope that didnt work, I put some load onto the disks and as soon as that happens over it goes, looks like I will be replacing the controller...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just trying to get all the data off of the array before replacing the card.
I am finding lots of the following errors in the vmkernel log:
LinSCSI: SCSILinuxCommand:2370 SCSI_ADAPTER_ISSUE_FAIL Stress counter triggered
Intermixed with other errors with "Couldn't heartbeat on" in them.
Just prior to replacing the card, I am going to replace the cables and see if that might get rid of these errors, stranger things have happened.
I also get I/O Errors when trying to download the 100GB vmdk file and it gets frustrating when it gets an I/O error at 98GB. I think this coincides with the heartbeat error above.
Overall these problems all see to only occur when the disk system is put under a great deal of pressure. It might crash when it gets above 30000KBps
When comparing the logs to my own server, I do not see any of these errors, my own server (which uses a 12 port 3 series adaptec) is rock solid and the ESX server I have run has not crashed since the day I installed it (around 7 months)
I have attached some of the PSOD screens.
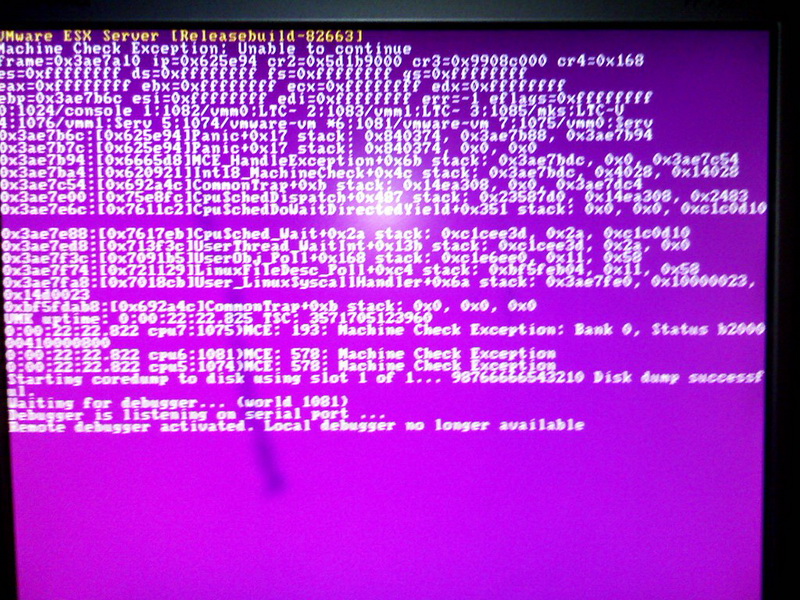{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Out of curiosity, what drives are you using? Are they on the Adaptec compatibility list?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
The drives are the same I am using on my own server which is 15.5K Seagate Cheetah disks. They are also on the compatibility list from Adaptec.
I have 2 arrays 1 mirror (2x 300GB cheetahs) and 1 raid 5 (4x 74GB cheetahs) I did have a raid 10 but I blew it away and recreated it as a RAID5, thought it might make a difference.
The RAID5 (used to be RAID10) seems to be the one causing all the trouble yet I was able to copy from one array to the other with no problems.
So I copied from the RAID5 to the Mirror and then downloaded the file to get it off, its a round about way but it worked.
After dinner Im going onsite and going to try the cable thing and then if that does not fix it, replace the controller.
I do have one disk I use for storage etc which is a Seagate 750GB Sata2. Ironically this seems to be the one that causes no trouble.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, thanks for your help
Yep they are on the list, I checked them in the adaptec bios on bootup, they are rev 002 of ST373455SS.
I ended up just replacing the controller and the cables, dont want to muck the client around more than they have been by switching out one component then another, will test on my own system.
I put an Adaptec 5405 in its place and just put one disk array on, so far no errors and its running nice and smooth.
I replaced the cables with cables out of my own system and put the suspect cables in my own system to see how they go, already having some issues with copying large files. I must admit when I got the cables I thought they looked cheap and nasty (adaptec cables too)
I spent all the time backing up the virtual machines. Thankfully it was not needed, the new card automatically picked up the old raid array and never skipped a beat. I was hoping that was going to happen, but you cannot be too carefull eh.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Well 2 hours into the day and it crashed again....
No IO errors and cannot see any clue as to why the ESX Server crashed (customer reset before checking PSOD)
I do get a warning that I have seen throughout:
Warning: CPU: 1003: cpu supports 38 bit physical address, but system is configured to limit the MTRR mask to 36 bits.
Also getting: vmkernel: 0:00:00:02.844 cpu0: 1024) WARNING: Host: 2499: irq 0 is not valid